 deʃhipu
deʃhipuThose are the slides from my talk for the Dublin 2018 Hackaday Unconference. Since the slides themselves contain only graphics to be explained in the talk itself, I'm also adding explanations below them. Unfortunately I have no idea what I actually said during the talk (I hope I didn't offend anyone or anything like that) — all I remember is red mist and then I woke up in the plane — so the comments are more what I *wanted* to say and less what I actually said.

Hello, my name is blah, blah, blah and so on. I mentioned the #PewPew FeatherWing and the #µGame projects and also I probably forgot to mention the #Display Module Survey project.
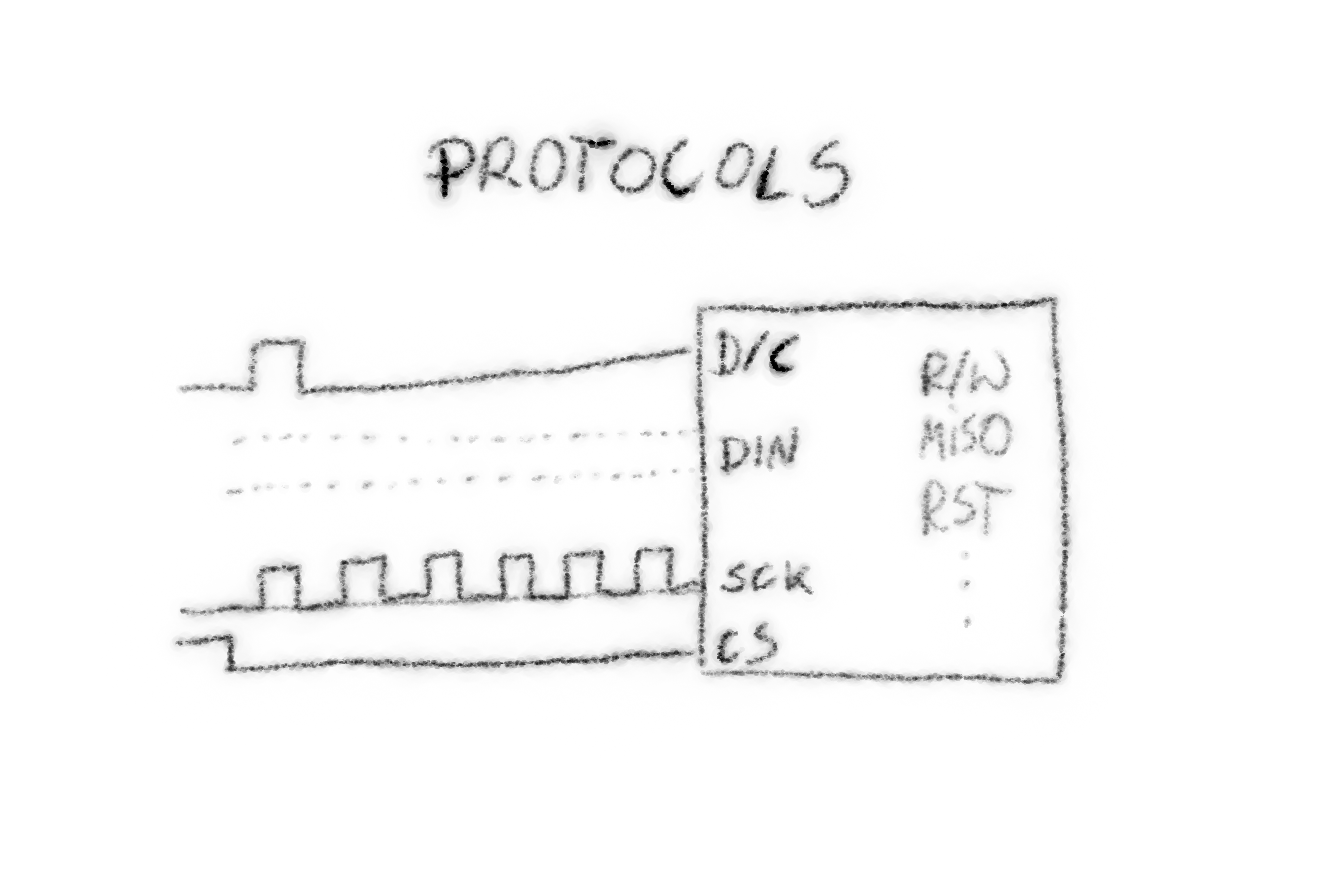
The way you speak to those modules: a quick explanation of the SPI protocol (you set the data line to the value you want to send, and you tug on the clock line to let the other side know when to read that value), and then the generalization of that into the parallel protocols. A quick mention of I2C and why it's usually too slow for this. I probably forgot to explain what the data/command line is for, and completely ignored the existence of the chip-select line. In any case, if you can you want to use the parallel protocol with as many lines, as you can spare.
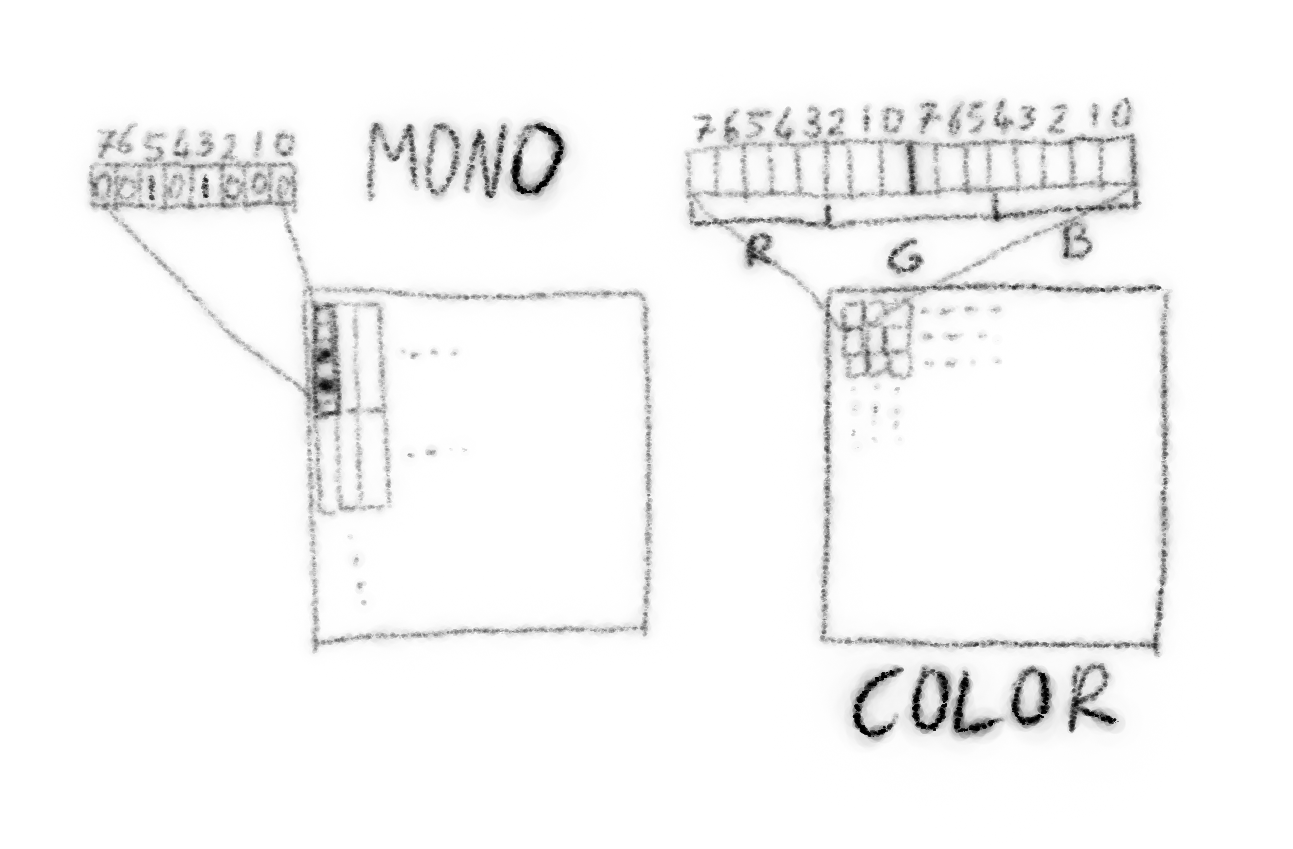
How the bits and bytes are arranged in the internal memory of the module, and how they map into the physical pixels of the displays. Usually you have one of two approaches: for monochrome displays, you have bit per pixel, and the pixels are grouped into one byte columns (or rows); for color displays, you have the RGB components encoded into bits in a 4-4-4, 5-5-5. 5-6-5 or 6-6-6 arrangement, depending on the selected color mode. The way you send that data to the display is that first you send a command that selects a rectangular area of the memory, and then you send the data to fill that area.
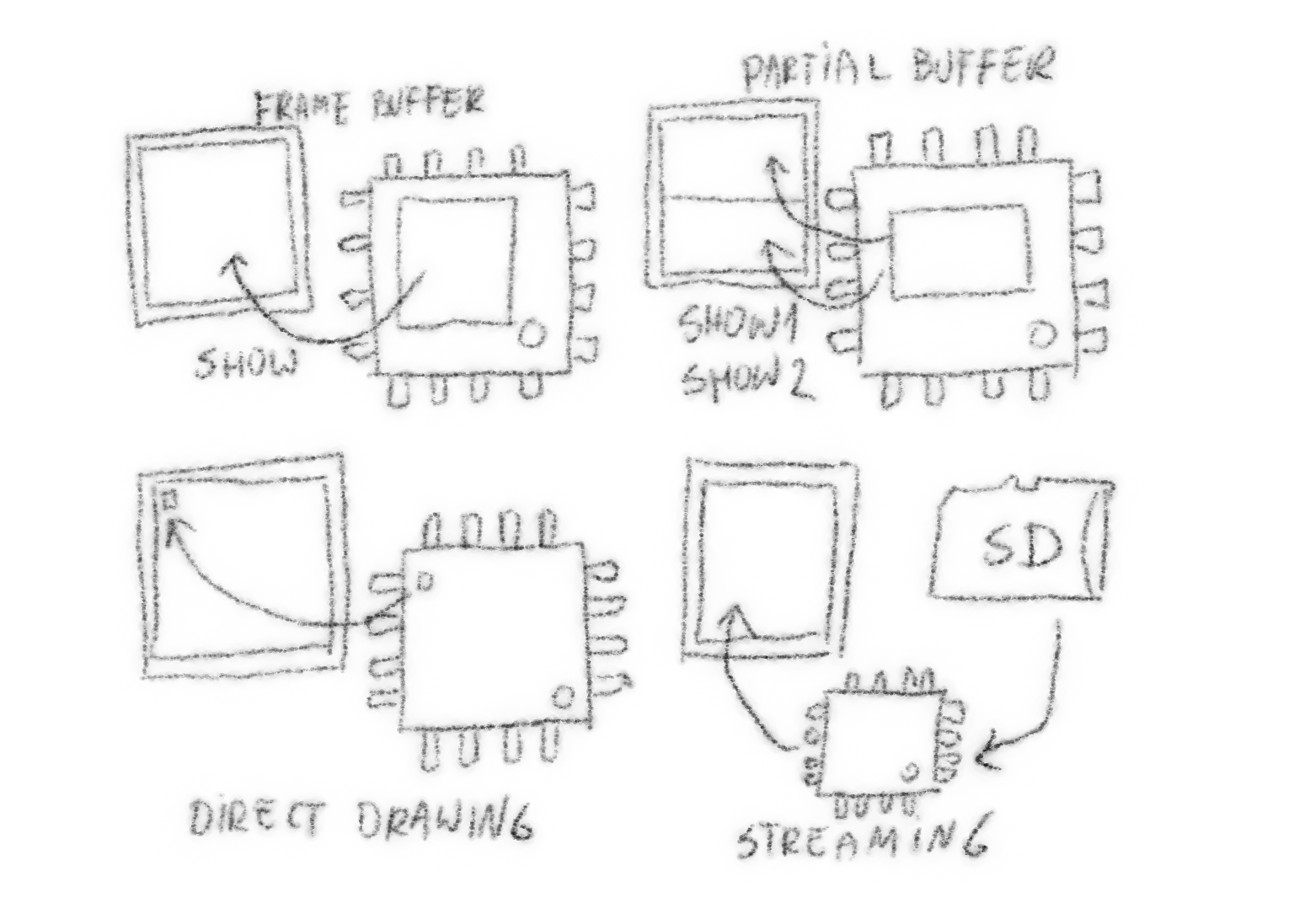
How most graphics libraries handle those displays. The first is a full frame buffer — you keep a copy of the display's memory, draw in that, and then send it to the display as a whole. The second is a partial buffer — when you don't have enough memory for the full one — you split the memory in several parts, and repeat all the drawing commands and the sending as many times as necessary. The third just sends individual pixels as you draw them — not only slow, but also lets you see the image being drawn. The last one is for displaying bitmaps that are sent from some source, such as flash memory or the network — you just pass the data on to the display, without really doing anything with it.
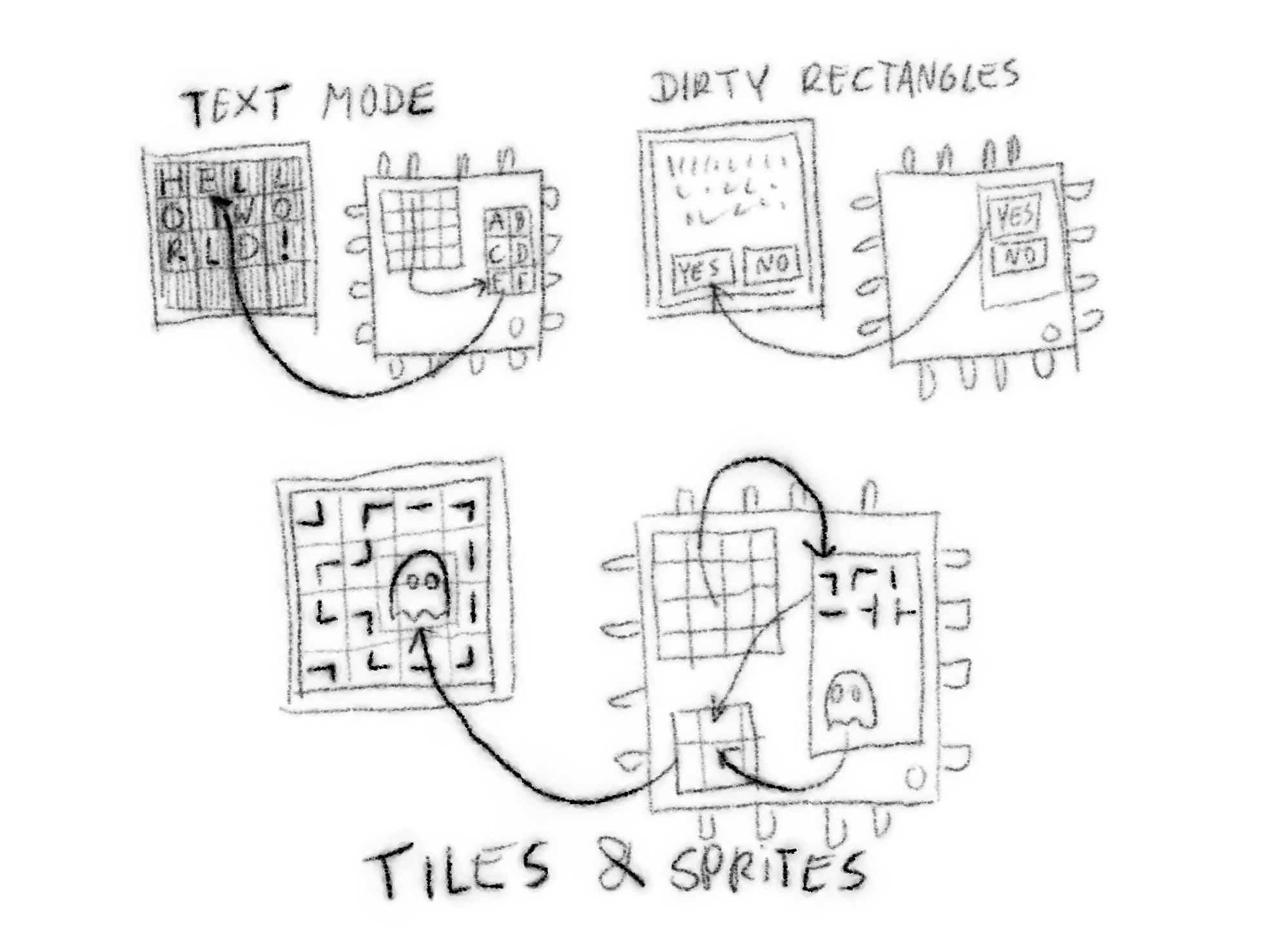
Smarter and more use case-specific methods of handling the display. Starts with a text mode, where each character has its place on the display, and you have a table with the bitmaps for all the characters, and a map of which cell has which character to display. Then you update just the individual character cells directly from your table as they change. Can also be optimized to update whole lines, etc. Then we have the dirty rectangles, where you still have a table with all the graphics you want to use — usually parts of your graphic interface — but they are not all the same size. They do have to all be rectangular, though, since you don't have any background information to fill the transparent pixels. Finally, the sprite-and-tile engine, like #Stage, a Tile and Sprite Engine, which draws the moving sprites as dirty rectangles, but fills the transparent parts of those with information taken from tiles similar to the text mode.
The final takeaway is that you can really speed things and do great stuff if you just first think about what you need exactly and use the algorithms suited for that, instead of just blindly using a ready library.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.