 Bob Miller
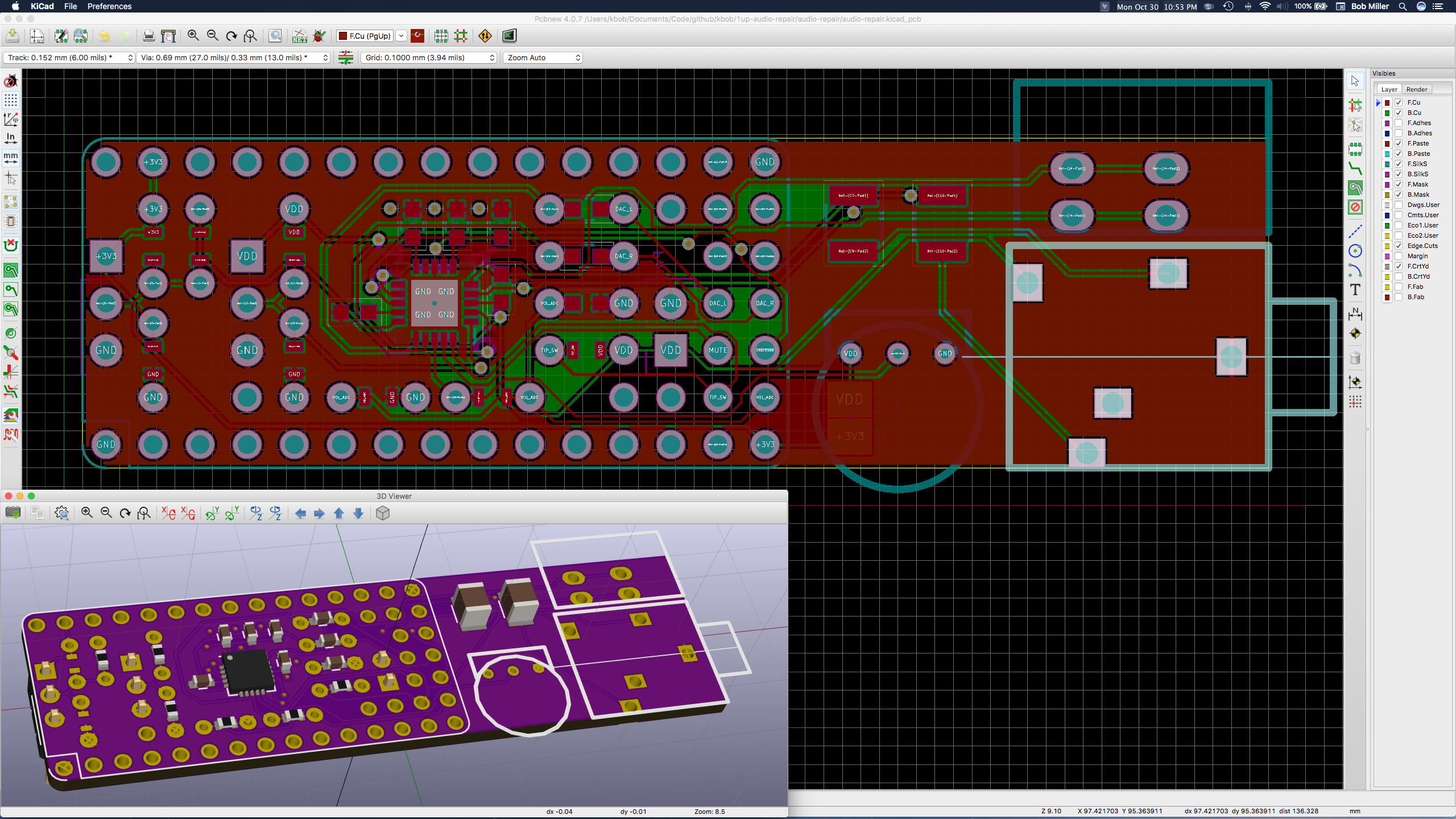
Bob MillerI have a 1Bitsy-1UP. My friend Piotr designed it. He made three of them, and he gave me one. It's a weird little handheld game console. You can read more about it here. It looks like an original Nintendo Game Boy, but it's a little smaller, and it has a couple of extra buttons. And it's from 2016, not 1989. So it has an STM32F4 MCU at 168 MHz, a color LCD screen, SD card, USB, and all the modern conveniences.
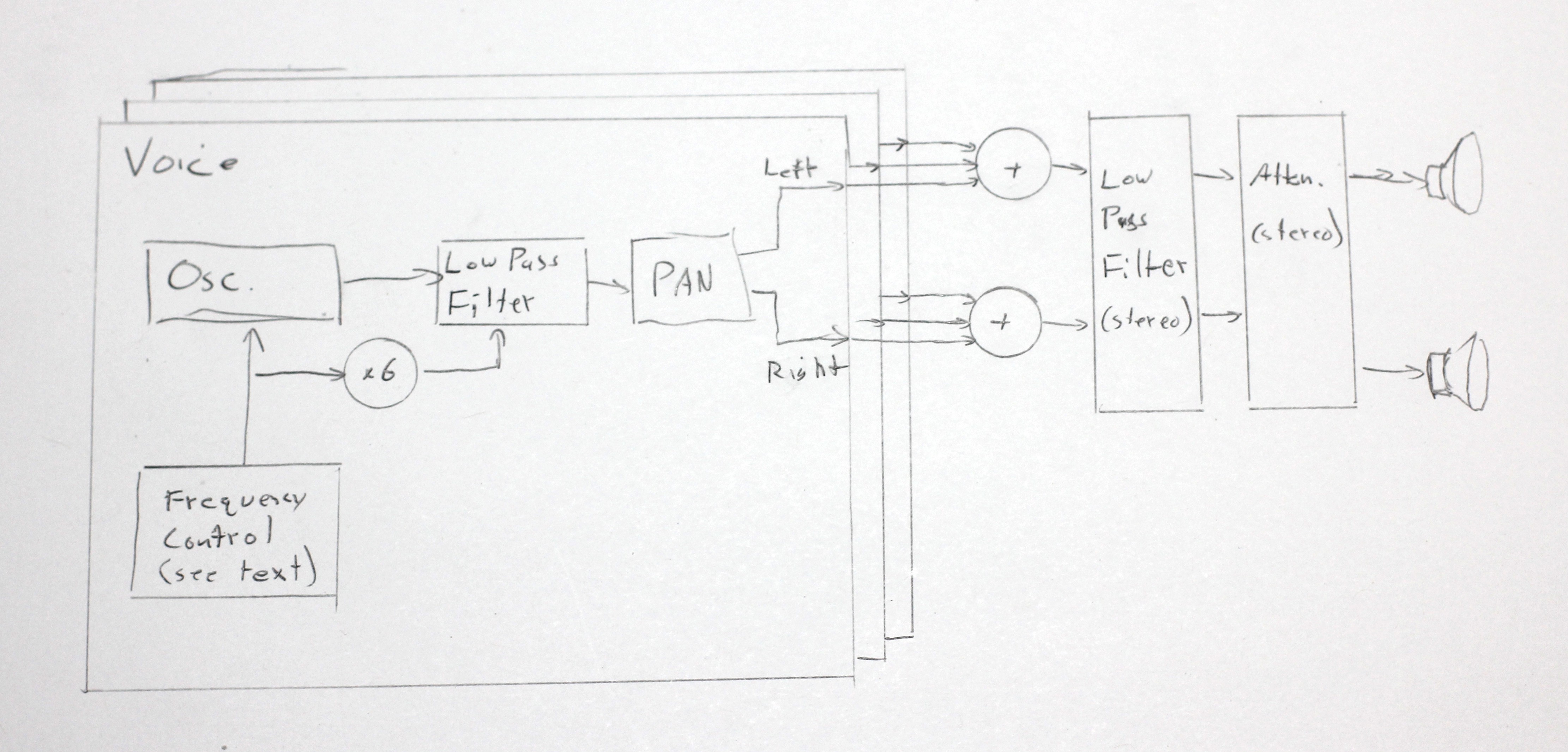
I wrote an audio driver for the 1UP, and that turned into an odyssey. But after the driver was done, I needed a good audio demo.
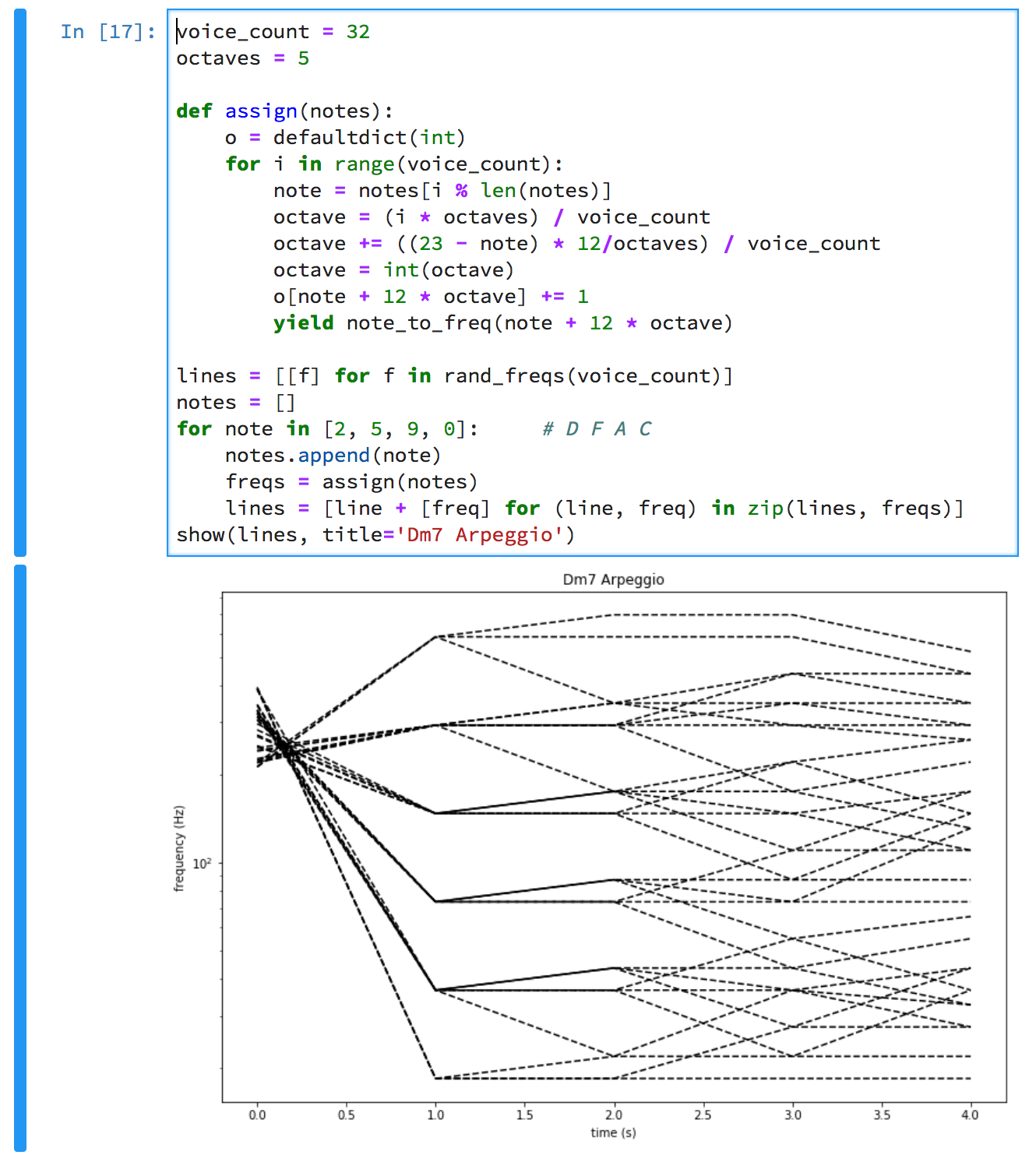
Meanwhile, I'd been thinking about the Deep Note sound that has appeared at the beginning of a lot of Lucas/Pixar movies. I was wondering whether it would be possible to make a synth that could play melodies in that heroic voice. How playable would it be? How would it sound to go from hall full of buzzing bees to chord, back to buzzing, then to another note or chord? It might be epic. It might be awful. It might even be epically awful.
So I have a game console looking for an audio demo, and I have a synth idea looking for an implementation. Maybe... Could I? Should I?
So I looked into it. Batuhan Bozkurt had already reconstructed a good facsimile of Deep Note in Supercollider and written about it.
There were unknowns.
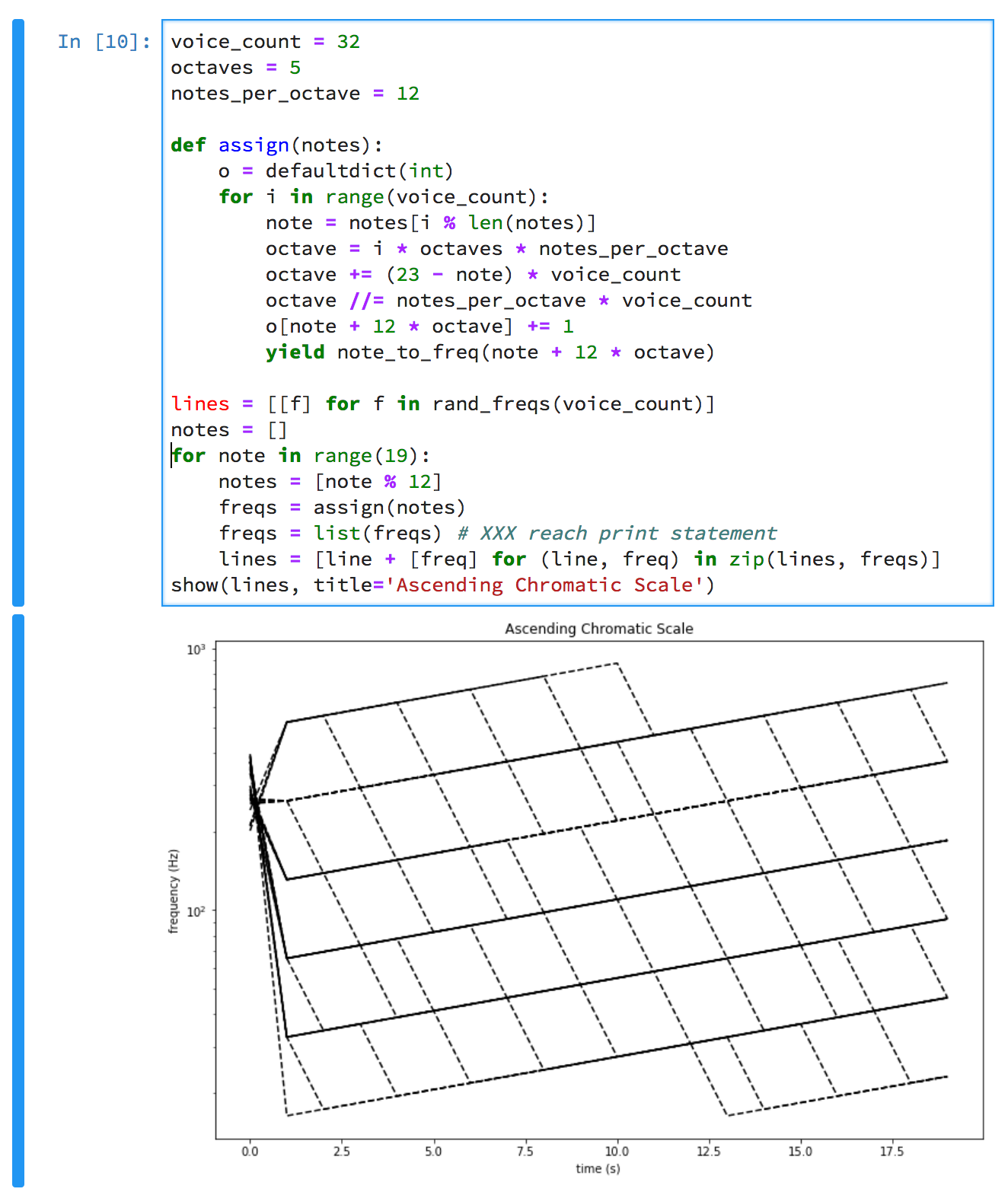
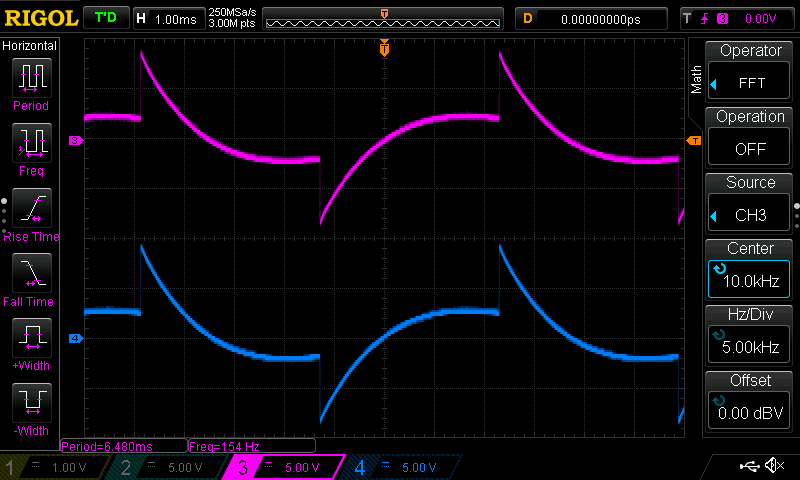
- Would Deep Note sound good in 12 bit audio?
- Is the STM32 fast enough to synthesize 30-ish crazy oscillators?
- How do you turn a gamepad into a music keyboard?
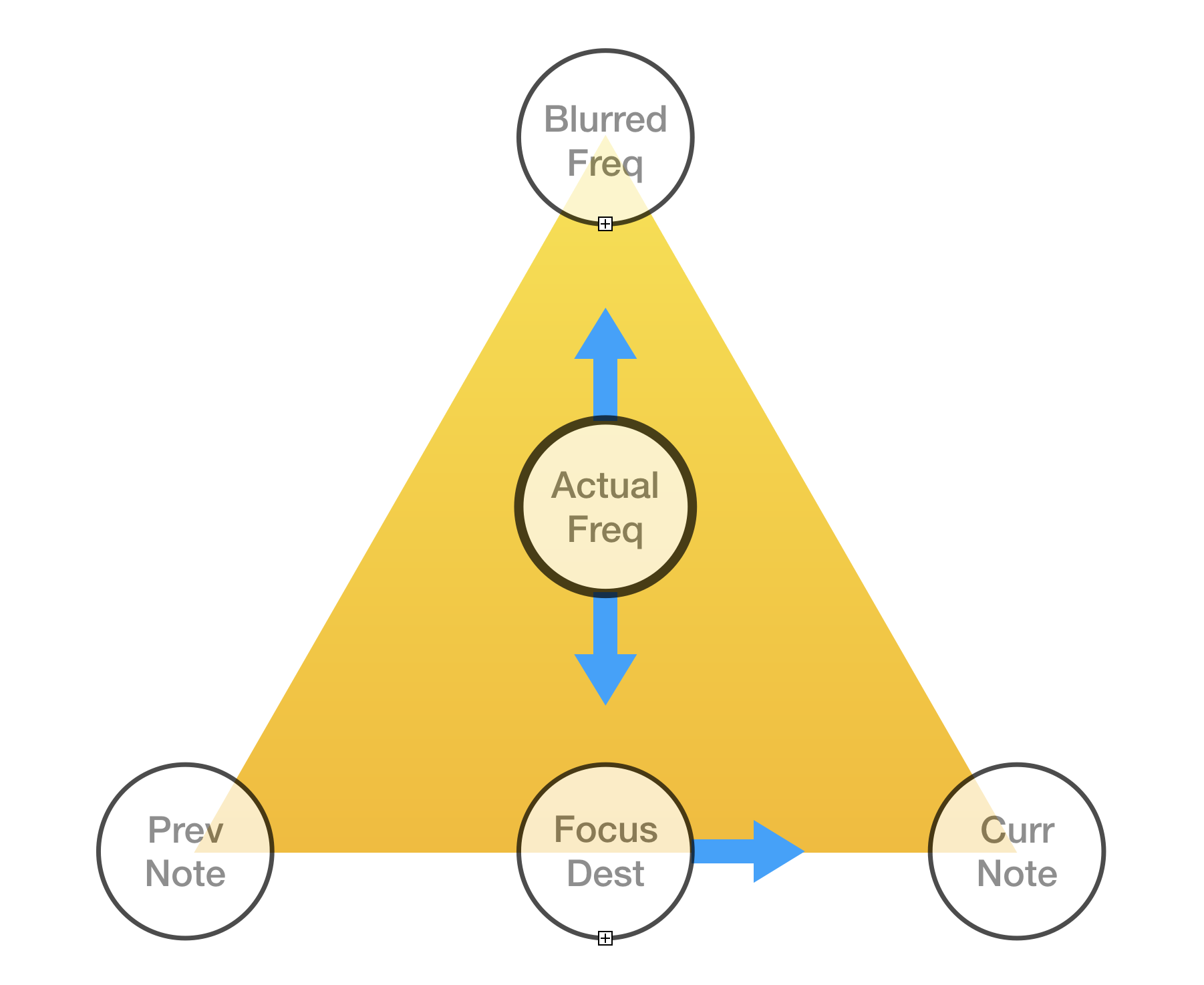
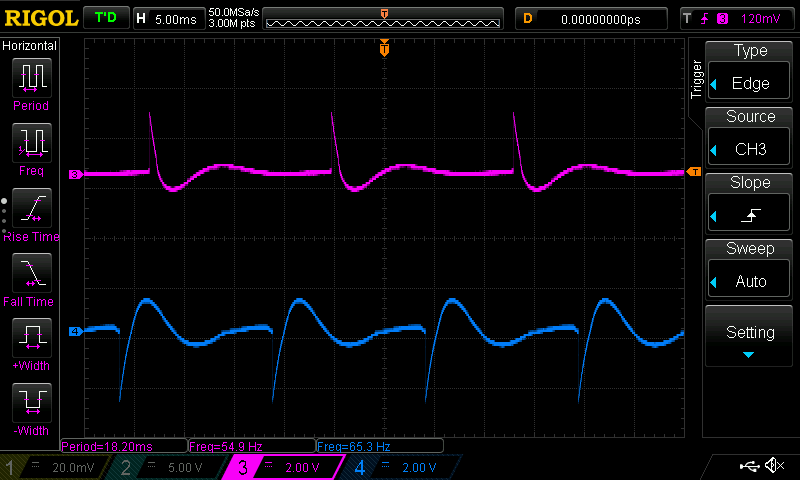
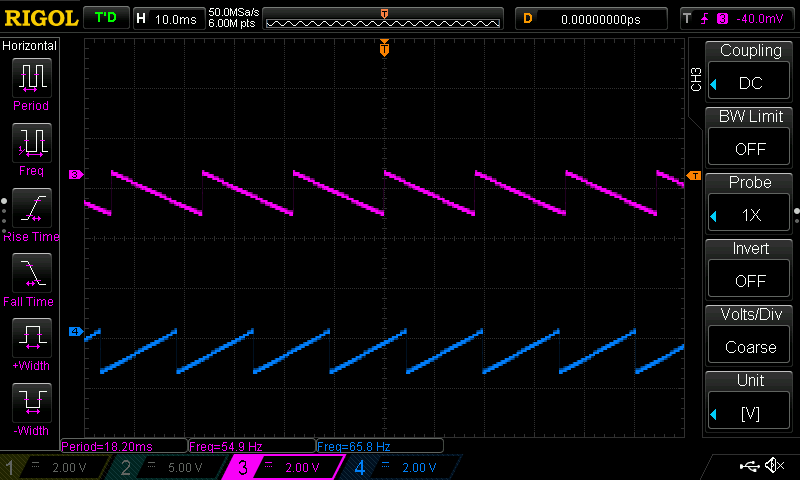
- How should it sound when a note ends?
- How should it transition from note to note?
So I had to find out.




 Hari Wiguna
Hari Wiguna
 deʃhipu
deʃhipu
 kutluhan_aktar
kutluhan_aktar
 Jorj Bauer
Jorj Bauer