 lion mclionhead
lion mclionheadWhile waiting 9 minutes for the onnx python library to load a model, lions remembered file parsers like these going a lot faster 30 years ago in C & taking a lot less memory. The C parser used in trtexec goes a lot faster.
The next idea was to edit the input dimensions in pose_deploy.prototxt
name: "OpenPose - BODY_25"
input: "image"
input_dim: 1 # This value will be defined at runtime
input_dim: 3
input_dim: 256 # This value will be defined at runtime
input_dim: 256 # This value will be defined at runtime
Then convert the pretrained model with caffe2onnx as before.
python3 -m caffe2onnx.convert --prototxt pose_deploy.prototxt --caffemodel pose_iter_584000.caffemodel --onnx body25.onnx
name=conv1_1 op=Convn
inputs=[
Variable (input): (shape=[1, 3, 256, 256], dtype=float32),
Constant (conv1_1_W): (shape=[64, 3, 3, 3], dtype=<class 'numpy.float32'>)
LazyValues (shape=[64, 3, 3, 3], dtype=float32),
Constant (conv1_1_b): (shape=[64], dtype=<class 'numpy.float32'>)
LazyValues (shape=[64], dtype=float32)]
outputs=[Variable (conv1_1): (shape=[1, 64, 256, 256], dtype=float32)]
It actually took the modified prototxt file & generated an onnx model with the revised input size. It multiplies all the dimensions in the network by the multiple of 16 you enter. Then comes the fixonnx.py & the tensorrt conversion.
/usr/src/tensorrt/bin/trtexec --onnx=body25_fixed.onnx --fp16 --saveEngine=body25.engine
The next step was reading the outputs. There's an option of trying to convert the trt_pose implementation to the openpose outputs or trying to convert the openpose implementation to the tensorrt engine. Neither of them are very easy.
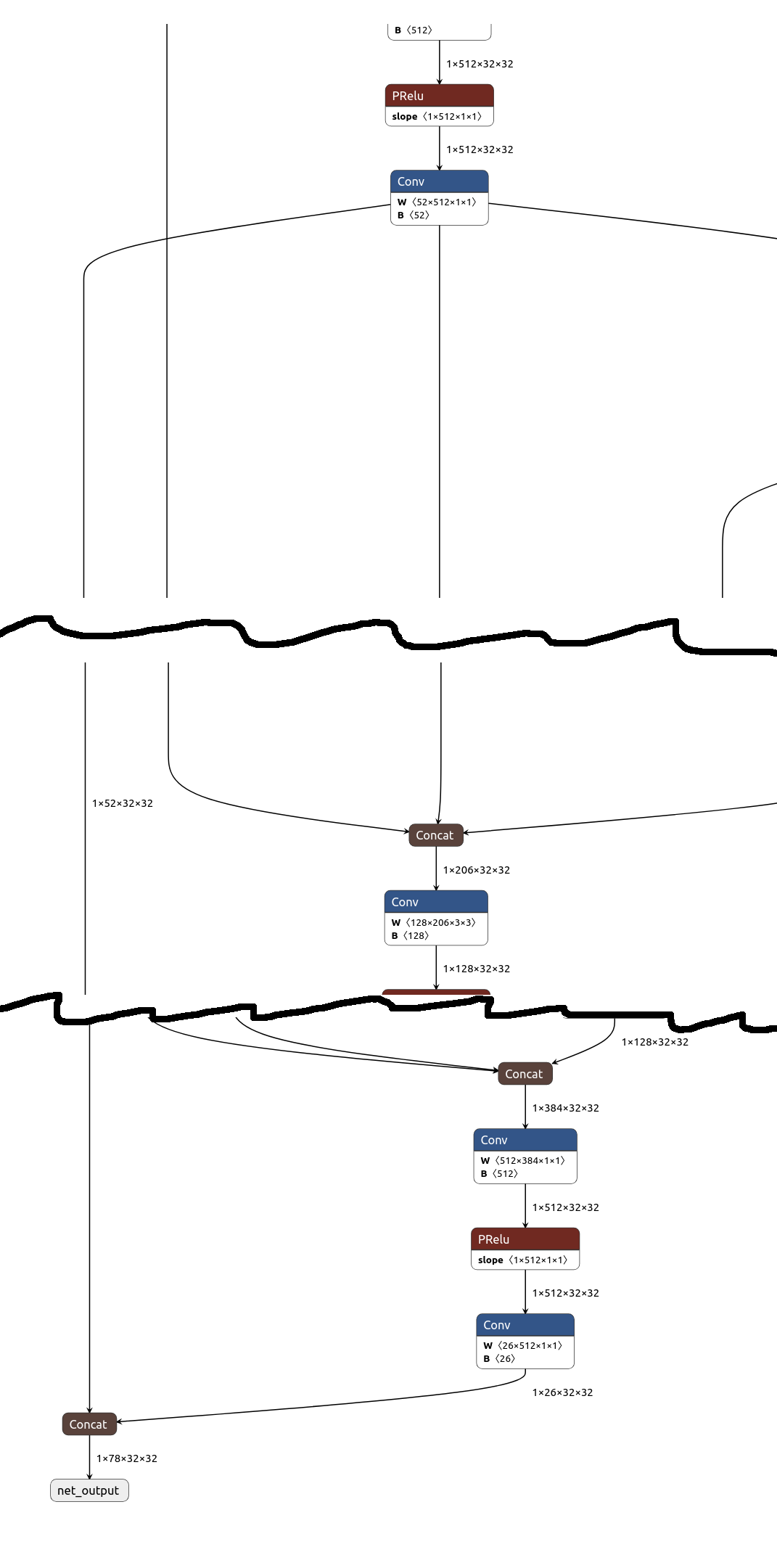
openpose outputs:
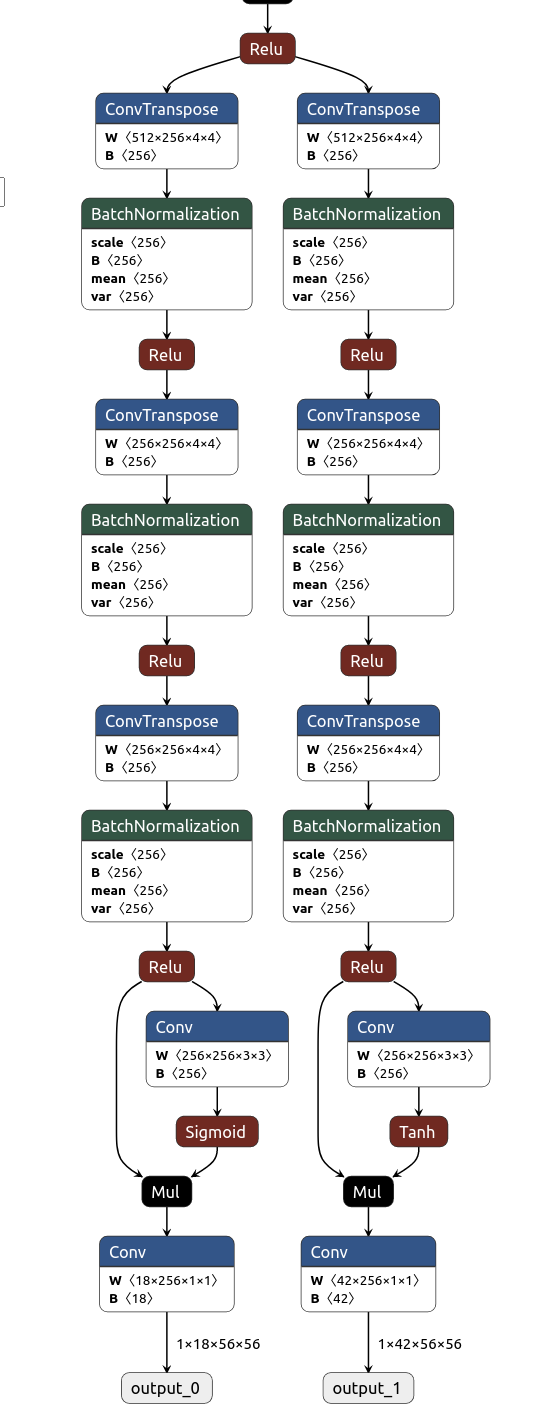
trt_pose outputs:
Tensorrt seems to look for layers named input & output to determine the input & output bindings.
The inputs are the same. TRT pose has a PAF/part affinity field in output_1 & CMAP/confidence map in output_0. Openpose seems to concatenate the CMAP & PAF but the ratio of 26/52 is different than 18/42. The bigger number is related to the mapping (CMAP) & the smaller number is related to the number of body parts (PAF).
There's a topology array in trt_pose which must be involved in mapping. It has 84 entries & numbers from 0-41.
A similar looking array in openpose is POSE_MAP_INDEX in poseParameters.cpp. It has 52 entries & numbers from 0-51.
The mapping of the openpose body parts to the 26 PAF entries must be POSE_BODY_25_BODY_PARTS. trt_pose has no such table, but it's only used for drawing the GUI.
The outputs for trt_pose are handled in Openpose::detect. There are a lot of hard coded sizes which seem related to the original 42 entry CMAP & 84 entry topology. Converting that to the 52 entry CMAP & 52 entry POSE_MAP_INDEX is quite obtuse.
The inference for openpose is done in src/openpose/net/netCaffe.cpp: forwardPass. The input goes in gpuImagePtr. The output goes in spOutputBlob. There's an option in openpose called TOP_DOWN_REFINEMENT which does a 2nd pass with the input cropped to each body. The outputs go through a similarly obtuse processing in PoseExtractorCaffe::forwardPass. There are many USE_CAFFE ifdefs. Converting that to tensorrt would be a big deal. The trt_pose implementation is overall a lot smaller & more organized.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.