 biemster
biemsterAfter hours of looking at hex values, searching for constants or pointers or some sort of pattern, comparing it with known data structures, and making importers for both C++ and python to no avail, I finally hit the jackpot:
When you look at the header of a proper tflite model you will see something like this:

Especially the TFL3 descriptor is present in all model files. The binary files in the superpack zip supposedly containing the models look like this:

They all have this 'N\V)' string on the same spot as the tflite model's descriptor, and nowhere else in the 100MB+ files. Then I also remembered being surprised by all these 1a values throughout all the binaries from the zip, and noticed they coincide with 00 values from the proper tflite models.
Now anybody who ever dabbled a bit in reverse engineering probably immediately says: XOR!
It took me a bit longer to realize that, but the tflite models are easily recovered xor'ing the files with the value in place of the 00's:
import sys
fname = sys.argv[1]
b = bytearray(open(fname, 'rb').read())
for i in range(len(b)): b[i] ^= 0x1a
open(fname + '.tflite', 'wb').write(b)
This will deobfuscate the binaries, which can than be imported with your favorite tensorflow lite API. The following script will give you the inputs and outputs of the models:
import tensorflow as tf
models = ['joint','dec','enc0','enc1','ep']
interpreters = {}
for m in models:
# Load TFLite model and allocate tensors.
interpreters[m] = tf.lite.Interpreter(model_path=m+'.tflite')
interpreters[m].allocate_tensors()
# Get input and output tensors.
input_details = interpreters[m].get_input_details()
output_details = interpreters[m].get_output_details()
print(m)
print(input_details)
print(output_details)
Now I actually have something to work with! The above script gives the following output, showing the input and output tensors of the different models:
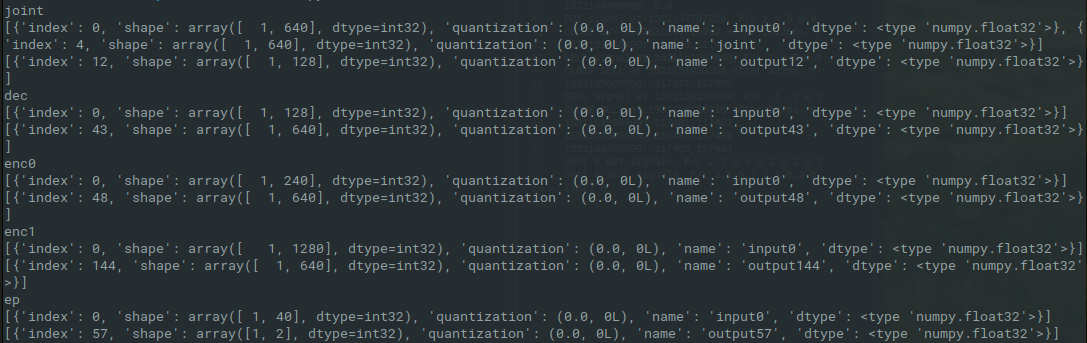
De decoder and both encoders have an output with length 640, and the joint has two inputs of length 640. I will have to experiment a bit what goes where, since the graph I made from the dictation.config and the diagram in the blog post don't seem to be consistent here.
With the dictation.ascii_proto and those models imported in tensorflow, I can start scripting the whole workflow. I hope the config has enough information on how to feed the models, but I'm quite confident now some sort of working example can be made out of this.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
heyy are you done ?
Are you sure? yes | no
nope..
Are you sure? yes | no
awesome work man!
Which tool you have used to decompile apk with so files?
Are you sure? yes | no
Thanks! I used apktool to decompile the main apk, but i did not go in the so files yet. User parameterpollution on HaD here apparently used ghidra, he wrote about it in the comment section of the project.
Are you sure? yes | no