 Yann Guidon / YGDES
Yann Guidon / YGDESAs the last log implies in the title, I want to compute and collect gPEAC to 1 million. Which means I'm trying fist to optimise the scanner to save some time. So I embarked in some code optimisation and the results were puzzling. For this session, I use the same "Intel(R) Core(TM) i7-2620M CPU @ 2.70GHz" as ever but IIRC the results were even more puzzling for later steppings and generations because power consumption optimisations, temperature management and clock scaling have become even more aggressive.
Almost two decades ago, I would get angered by weird benchmarking results as my laptop's Pentium ]|[ would halve its clock to maintain its small TDP (maybe 25W or so). Today, it's even more creepy, even though we have multi-core processors. When one core runs at 100%, activity on another core will affect the temperature and scale back the overall clock. Worse : changing the laptop's position could increase the airflow and influence the results.
Conclusion : efficient cooling of the CPU is more efficient than micro-optimisation of code in the latest generations. So is optimisation dead ?
It's now a matter of quantifying and isolating the factors. The baseline is a program that runs for more than 2 minutes while scanning primary gPEAC orbits from 2 to 10000. As I changed coding styles and approaches, I saw results vary a lot in unexpected ways. Then I decided to run one version 5 times to examine variance. I was pretty shocked. So I started a longer run and logged the results. I saw runtimes varying from 1m53s to 2m42s ! The log was empty due to a coding mistake (sleep or code, you have to choose) so I ran a 3rd, longer session. This time I added a measure of the CPU temp in the hope to draw a correlation. Yeah only the temperature got logged (I forgot the 2>&1) and I should also add the CPU frequencies in the logs. Here is the next attempt:
for i in $( seq 1 30 ); do
echo -n $(cat /sys/class/thermal/thermal_zone6/temp )" "
echo -n $(grep 'cpu MHz' /proc/cpuinfo | sed 's/.*[:]//' )
echo -n " "
/usr/bin/time -f '%U' ./t.sh
done 2>&1 | tee t3.times
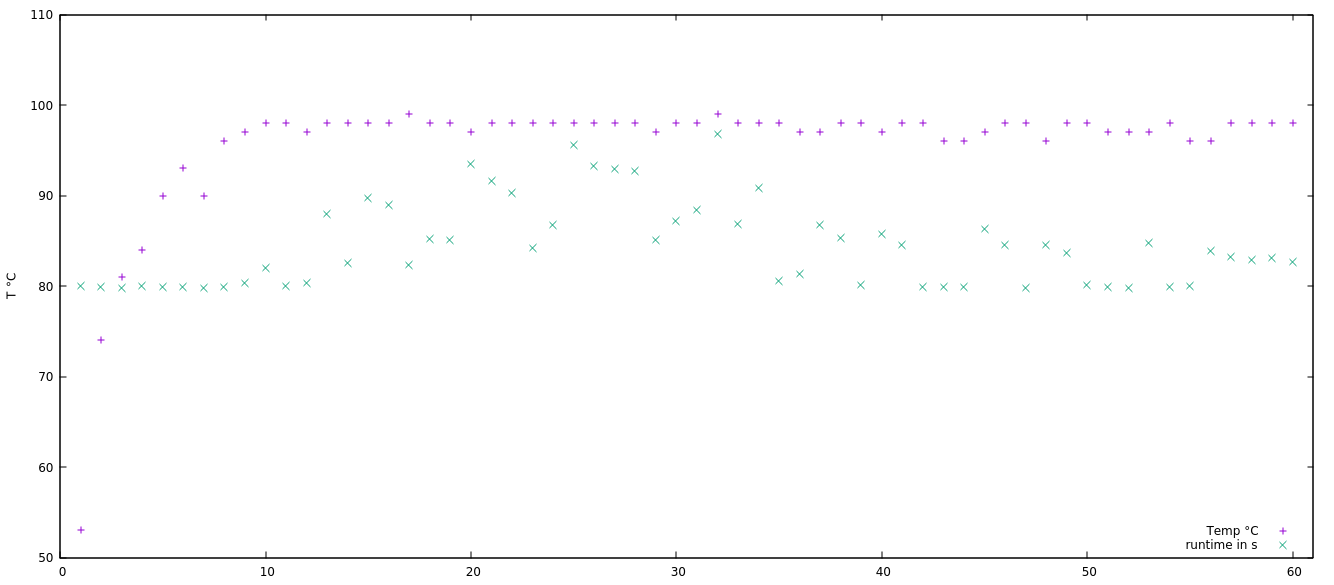
min : 29s92
max : 35s59
With a single CPU attributed to the program, no other significant program running, and a verified CPU clock speed stuck at 2.7GHz, a variance of 16% is alarming and makes me unable to compare program efficiencies as before.
....
So now, what ? How is it even possible to benchmark anything if the platform reacts and plays against us ?
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
I felt pretty ripped of when I found that my i7 laptop had 4 cores not the 8 in an i7 desktop. Then I found that it could run one core at 100% continuously. That's it. It's basically a single core cpu with some other low power cores for a bit of background processing. The i5 laptop eats it running matlab benchmarks.
Intel and HP totally lost any credibility, at that point, and I stopped upgrading.
Are you sure? yes | no
What generation/stepping is your laptop ?
The old 2nd gen i7 laptop is my everyday workhorse but when needed I bring in the 10750H and its 6 cores. It gets weird then because it has a way more dynamic and sensitive frequency scaling. Anything affects it. Blow on it and the performance changes.
Are you sure? yes | no
heh. just wait until your "platform" is a conversational AI thing that never reacts to a prompt the same way twice.
Are you sure? yes | no
I must be stuck in the ol'Pentium days when benchmarking was "super easy, barely an inconvenience"... Just use RDTSC under DOS and that's all.
Today we must use overly complex OS's, on multicore, multithreaded, multi-level caches where the slightest thing affects all the rest. As a user program, accessing the performance counters in a portable way is barely manageable.
Are you sure? yes | no
Virtuality all the way down.
...Maybe it's fair to say that virtualization is a performance multiplier, making a computy thing pretend to be bigger & faster than the real sand and rust parts inside. So performance depends on the multiplier and "optimization" includes figuring out what makes the multiplier bigger, or not, and how to monopolize the benefit mumble foo.
Are you sure? yes | no