 lion mclionhead
lion mclionheadCustom efficientdet was officially busted on the jetson nano & it was time to try other models. The attraction to efficientdet might have been the speed of the .tflite model on the raspberry pi, the ease of training it with modelmaker.py & that it was just a hair away from working on the jetson, but it just couldn't get past the final step.
The original jetbot demo used ssd mobilenet v2. That was the cutoff point for the jetson nano. SSD mobilenet seems to be enjoying more recent coverage on the gootubes than efficientdet because no-one can afford anything newer. Dusty guy showed it going at 22fps. The benchmarks are all over the place.
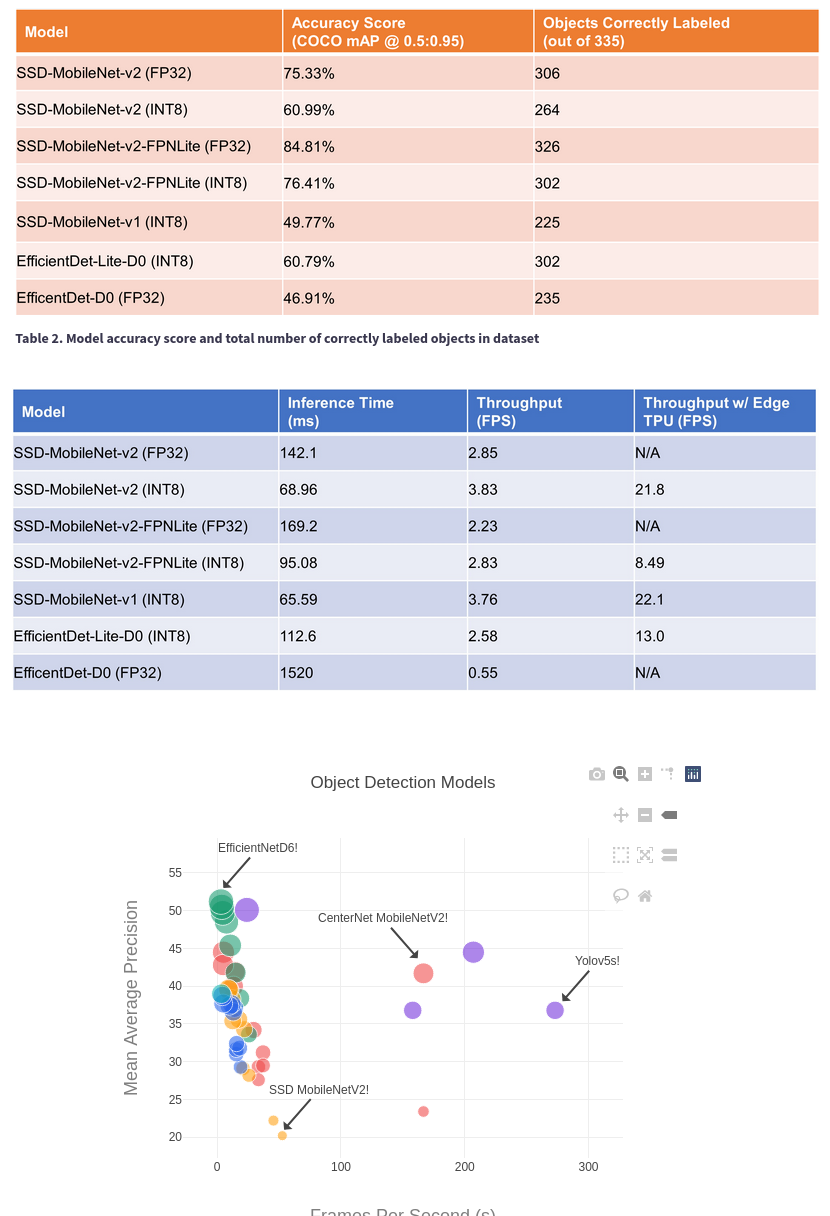
It depends on data type, data set, & back end. Everything at a given frame rate & resolution seems to be equivalent.
Dusty guy created some documentation about training ssd mobilenet for the jetson nano.
https://github.com/dusty-nv/jetson-inference/blob/master/docs/pytorch-ssd.md
He continued to document a variety of different models on the newer jetson products until 2021.
https://github.com/dusty-nv/jetson-inference/tree/master
They disabled video commenting right after the lion kingdom tuned in. The woodgrain room is in Pennsylvania. Feels like the jetson line is generally on its way out because newer single board computers are catching up. The jetson nano is 1.5x faster in FP32, 3x faster in FP16, than a raspberry pi 4 in INT8.
Sticking to just jetson nano models shown in the video series seems to be the key to success. There's no mention of efficientdet anywhere. Noted he trained ssd mobilenet on the jetson orin itself. That would be a rough go on the nano. Gave efficientdet training a go on the jetson.
root@antiope:~/automl/efficientdet% OPENBLAS_CORETYPE=CORTEXA57 python3 main.py --mode=train --train_file_pattern=../../train_lion/pascal*.tfrecord --model_name=efficientdet-lite0 --model_dir=../../efficientlion-lite0.jetson --ckpt=../../efficientdet-lite0 --train_batch_size=1 --num_examples_per_epoch=1000 --hparams=config.yaml
It needed a commented out deterministic option, but ran at 1 epoch every 15 minutes. It would take 3 days for 300 epochs or 17 hours for 66 epochs. The GTX 970M ran at 2 minutes per epoch. Giving it a trained starting checkpoint is essential to reduce the number of epochs, but it has to be the same number of classes or it crashes. The swap space thrashes like mad during this process.
After 80 epochs, the result was exactly the same failed hit on tensorrt & good hit on model_inspect.py, so scratch the training computer as the reason.
--------------------------------------------------------------------------------------------
https://github.com/dusty-nv/jetson-inference/blob/master/docs/pytorch-ssd.md
SSD mobilenet has a new dance for the training set. The annotations have to be in files called sub-train-annotations-bbox.csv, sub-test-annotations-bbox.csv The jpg images have to be in subdirectories called train & test. As an extra twist, train_ssd.py flipped the validation & test filenames.
Label.py needs train_lion/train, train_lion/test directories
Then it needs CSV_ANNOTATION = True
Then there's a command for training
python3 train_ssd.py --data=../train_lion/ --model-dir=models/lion --batch-size=1 --epochs=300
This one doesn't have an easy way of disabling the val step. It needs vals to show what epoch was the best. At least it's fast in the GTX 970. Then the ONNX conversion is fast.
python3 onnx_export.py --model-dir=models/lion
This picks the lowest loss epoch which ended up being 82.
time /usr/src/tensorrt/bin/trtexec --fp16 --workspace=2048 --onnx=/root/ssd-mobilenet.onnx --saveEngine=/root/ssd-mobilenet.engine
The input resolution is only 300x300. Helas, inference in C++ is an involved process described in
https://github.com/dusty-nv/jetson-inference/blob/master/c/detectNet.cpp
https://github.com/dusty-nv/jetson-inference/blob/master/examples/detectnet/detectnet.cpp
Dumponnx.py gives the inputs & outputs.
Variable (input_0): (shape=[1, 3, 300, 300], dtype=float32)
Variable (scores): (shape=[1, 3000, 2], dtype=float32)
Variable (boxes): (shape=[1, 3000, 4], dtype=float32)
Lions have learned 1,3,300,300 is planar RGB & 1,300,300,3 is packed RGB.
detectNet.cpp supports many models. detectNet::postProcessSSD_ONNX was the one for SSD mobilenet.

Results with the custom dataset were pretty unsatisfying, worse than pretrained efficientdet, but went at 40fps. This one could scan 2/3 of every frame. Some filtering is required to erase a bunch of overlapping hits, adapt the minimum score. Sometimes it doesn't get any hits at all. The scores are highly erratic. Sometimes they're all above 0.9. Sometimes they're all above 0.5. Normalization was critical. It might benefit from several normalization passes.
Using a model that was officially ported to the jetson nano was so much faster & easier than the 3rd party models, it might be worth trying their official posenet instead of an object detector. Lions previously documented it going at 12fps as TRT_POSE. That would convert to 5fps with face detection. Others on the gootube didn't even get it going that fast.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.