 lion mclionhead
lion mclionheadIt became clear the jetson isn't viable unless it matches the frame rate & robustness of the raspberry pi. After the experiments with SSD mobilenet, trt_pose, body_25, efficientdet remanes the only model which can do the job. The problem is debugging intermediate layers of the tensorrt engine. The leading method is declaring the layers as outputs in model_inspect.py so the change applies to the working model_inspect inference & the broken tensorrt inference.
This began with a ground up retraining of efficientdet with a fresh dataset.
root@gpu:~/nn/yolov5# python3 label.py
root@gpu:~/nn/automl-master/efficientdet# PYTHONPATH=. python3 dataset/create_coco_tfrecord.py --image_dir=../../train_lion --object_annotations_file=../../train_lion/instances_train.json --output_file_prefix=../../train_lion/pascal --num_shards=10
root@gpu:~/nn/automl-master/efficientdet# python3 main.py --mode=train --train_file_pattern=../../train_lion/pascal*.tfrecord --model_name=efficientdet-lite0 --model_dir=../../efficientlion-lite0 --train_batch_size=1 --num_examples_per_epoch=1000 --num_epochs=100 --hparams=config.yaml
Noted the graphsurgeon hack
https://hackaday.io/project/190480-jetson-tracking-cam/log/221260-more-efficientdet-attempts
to convert int64 weights to int32 caused a bunch of invalid dimensions.
StatefulPartitionedCall/concat_1 (Concat)
Inputs: [
Variable (StatefulPartitionedCall/Reshape_1:0): (shape=[61851824029695], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_3:0): (shape=[15466177232895], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_5:0): (shape=[3869765533695], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_7:0): (shape=[970662608895], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_9:0): (shape=[352187318271], dtype=float32)
]
Outputs: [
Variable (StatefulPartitionedCall/concat_1:0): (shape=None, dtype=float32)
]
The correct output was:
StatefulPartitionedCall/concat_1 (Concat)
Inputs: [
Variable (StatefulPartitionedCall/Reshape_1:0): (shape=[None, 14400, 4], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_3:0): (shape=[None, 3600, 4], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_5:0): (shape=[None, 900, 4], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_7:0): (shape=[None, 225, 4], dtype=float32)
Variable (StatefulPartitionedCall/Reshape_9:0): (shape=[None, 81, 4], dtype=float32)
]
Outputs: [
Variable (StatefulPartitionedCall/concat_1:0): (shape=[None, 19206, 4], dtype=float32)
]
That didn't fix the output of course.
------------------------------------------------------------------------------------------------------------------------
There are no tools for visualizing a tensorrt engine.
There is a way to visualize the frozen model on tensorboard. After a bunch of hacky, undocumented commands
OPENBLAS_CORETYPE=CORTEX57 python3 /usr/local/lib/python3.6/dist-packages/tensorflow/python/tools/import_pb_to_tensorboard.py --model_dir ~/efficientlion-lite0.out --log_dir log
OPENBLAS_CORETYPE=CORTEX57 tensorboard --logdir=log --bind_all
It shows a pretty useless string of disconnected nodes.
You're supposed to recursively double click on nodes to get the operators.
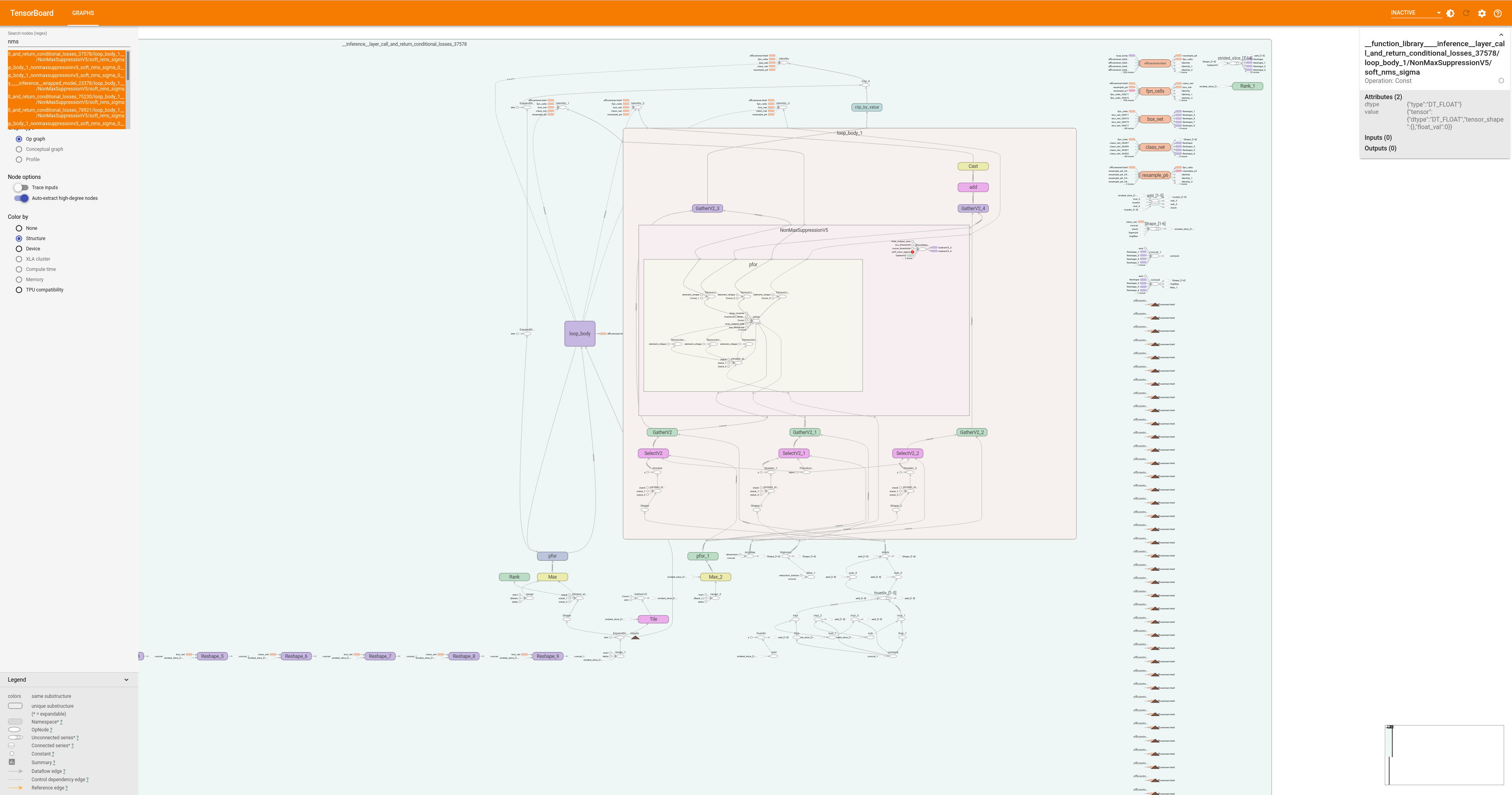
There's a minimal search function. It merely confirmed the 2 models have the same structure, as graphsurgeon already showed. The problem was the weights.
So a simple weight dumper truckcam/dumpweights.py showed pretrained efficientdet-lite0 to have some weights which were a lot bigger than efficientlion-lite0 but both models were otherwise in equivalent ranges. There were no Nan's. It was previously shown that fp32 & fp16 failed equally in tensorrt. It couldn't be the conversion of the weights to fp16.
------------------------------------------------------------------------------
The input was the only possible failure point seen. The best chance of success was seen as dumping the raw input being fed by model_inspect.py but there were no obvious ways to access that data in python. All the ideas from chatgpt failed.
Another idea was to feed model_inspect.py the precompiled efficientlion engine. model_inspect.py has a tensorrt benchmarking mode, but it can't compile the engine. If it ran a precompiled engine, it could prove the input was the problem.
At best, face detection wasn't going to be very functional on the jetson because the camera angle was too oblique. The only thing the jetson would offer was a higher efficientdet frame rate, but the raspberry pi was doing pretty well with only 7fps. Without face tracking, the jetson could use its port of body_25. Body_25 was possible because its interface was in C & that allowed low level access to the input data.
That would require comparing robustness of body_25 on the jetson to robustness of efficientdet on the raspberry pi. Body_25 can scan the full frame at 10Hz. Efficientdet can scan only 1/3 frame at 7Hz.
The decision was made to declare custom efficientdet non functional on the jetson nano & possibly compare efficientdet on the raspberry pi to body_25 on the jetson.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.