 joey castillo
joey castilloNOTE: This project log was originally posted on 08/13/2023 at 21:28 EDT, but due to a misunderstanding, it had to be deleted and remade.
OK, right: languages. Where we last left this topic I was introducing Babel, the Open Book’s solution for displaying texts in all the languages of the world. I mentioned that it was a bit like an old school character ROM in a computer from the DOS era, except that instead of a few kilobytes, the Open Book has (up to now) used a two-megabyte SPI Flash chip, packed to the gills with well over 60,000 bitmap glyphs for every language on earth. 

GNU Unifont, our bitmap font of choice, is mostly an 8x16 bitmap font, which makes it easy to store glyphs: each 8x16 character is sixteen bytes long, with each byte representing the state of one line of pixels. So, for example, the ASCII letter A has a byte representation like this:
00 00 00 00 18 24 24 42 42 7E 42 42 42 42 00 00
…and it looks like this. You can almost visualize how the 00’s correspond to empty lines without pixels, the 7E represents the crossbar with nearly all pixels set, and the repeated 42’s represent the sturdy legs that keep the letter from tipping over:

The point though is that this glyph fits in 16 bytes, and if our goal is to support the whole Basic Multilingual Plane — which has code points that range from U+0000 to U+FFFF — you get the sense that naïvely, we could create a lookup table where each character occupies 16 bytes. Then we could look up a character by multiplying its code point by 16: for code point U+0041 (ASCII 65, the letter ‘A’), we could multiply 65 by 16 and expect to find 16 bytes of bitmap data right there.
Alas, it’s not quite that simple. Remember, I said that Unifont was only mostly 8x16. The reality is, some languages' glyphs don’t fit into a tall skinny 8x16 bitmap. Some characters need more room to breathe. So GNU Unifont also includes a lot of double-width characters that are 16x16, like this Devanagari letter A:
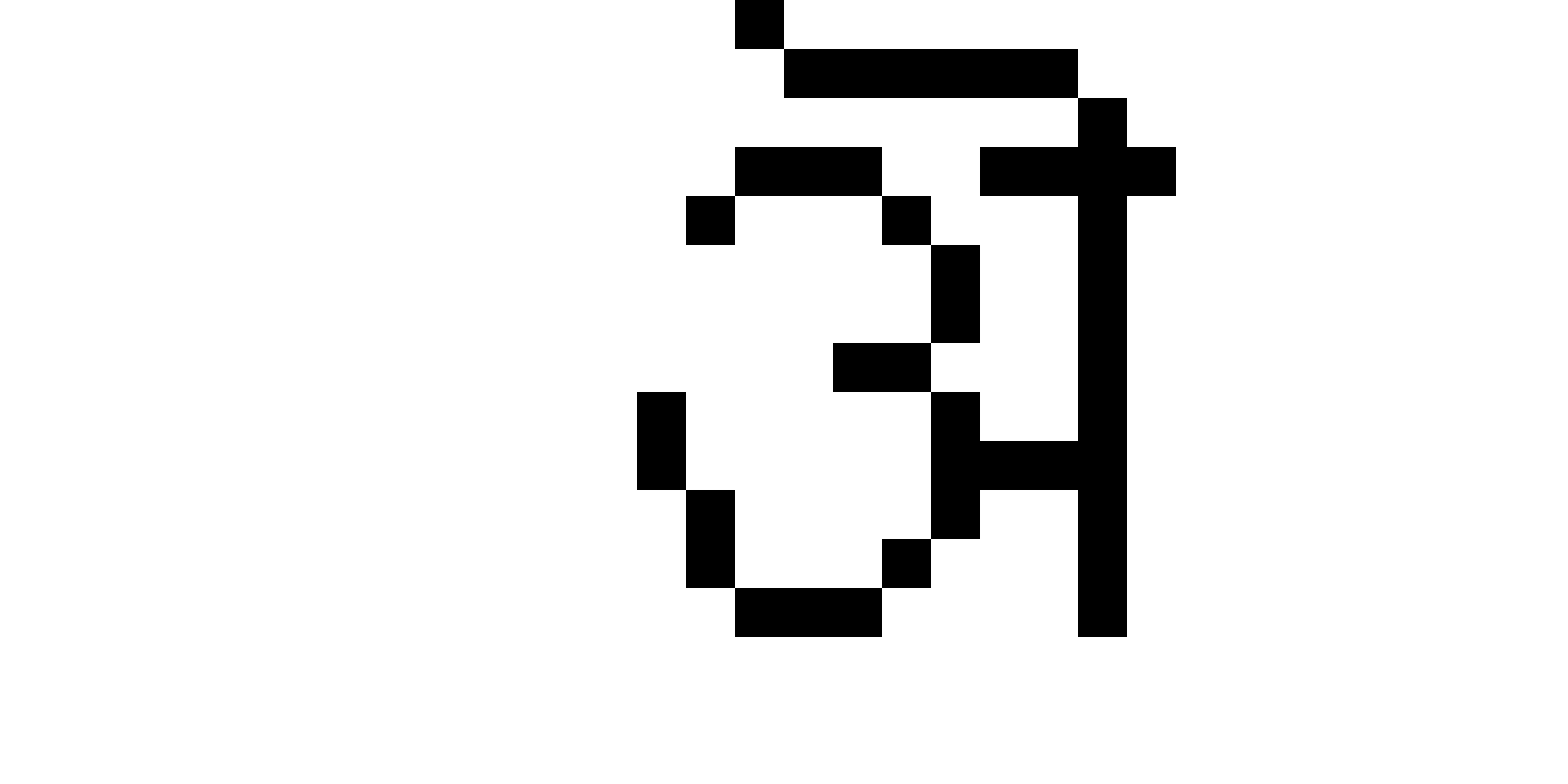
This glyph is wider, and it requires 32 bytes to represent it. Needless to say, you can’t have a constant time lookup table when some entries are 16 bytes long and others are 32.
What to do?
I suppose we could make our lookup table 32 bytes wide, and just accept that some characters only use the first half of that. The Devanagari ‘A’ could occupy its 32 bytes, and we’d just have to pad out the ASCII ‘A’ with 16 bytes of zeroes. Technically, this would work! It involves a lot of wasted space, but 32 bytes × 65,535 code points = 2,097,120 bytes — just barely small enough to fit into our 2 megabyte Flash chip, with 31 bytes to spare.
And if we have all the glyphs, we have all the languages, right?
…right?
Alas — once again — it’s not quite that simple. When it comes to language, nothing is simple.
Code points and characters, nonspacing marks, text direction and connected scripts (oh my!)
As it turns out, there’s a lot more to rendering text than having all the glyphs. For one thing, not only is not every code point assigned, not every code point even represents a character. Some code points represent accent marks or diacritics. Others might be control codes that do things like override the direction of a run of text.
Wait: text direction? Yes, as it turns out, not every language reads from left to right. Hebrew and Arabic in particular render from right to left — and Unicode specifies that when a character with right-to-left affinity appears in a run of text — משהו כזה — the direction of the text run needs to switch until a character with a left-to-right affinity appears.
Not only that, some scripts like Arabic require connected forms to display correctly: a run of letters (م ث ل ه ذ ه) need to be connected (مثل هذه) not just to appear legible, but because it’s simply incorrect to render them disconnected. It’s not how the language works.
Babel is going to have to obey all of these rules to display the world’s languages, and that means we need space to store this sort of metadata. Luckily, in our naïve implementation above, there was a lot of wasted space: all the empty bitmaps at unassigned code points, and the wasted space in half-width characters. If we could just reclaim that space, we might be able to free up enough room to store this metadata about each of our characters.
Still, we’re going to need to come up with a scheme to store all that data and access it in a performant way.
babel.bin: Lookup Tables and Metadata
Okay: so for performance reasons, we need to use a lookup table. To unpack what that means: we need for some information about code point 0 to be at an address (n), and we need the same information for code point 500 to be at address (n + 500 * c), where c is some constant number of bytes. Previously, we stored a lookup table of bitmaps. Instead, what if we just stored a lookup table of metadata?
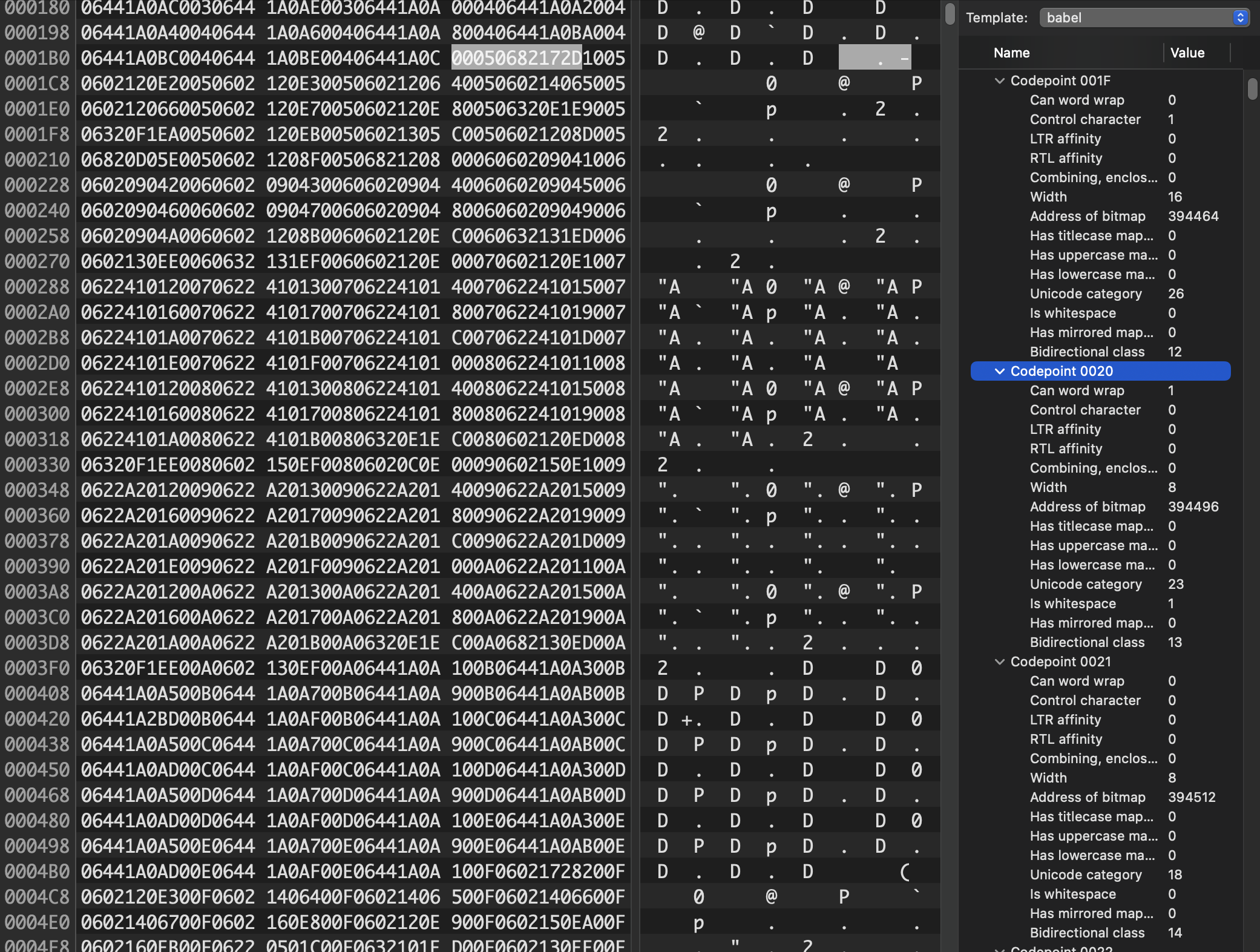
Well — spoilers! — that’s exactly what we did. At the very beginning of our SPI Flash chip, there’s a header, and then 65,536 six-byte metadata structures. This metadata contains flags for things like word wrapping opportunities, bidirectional layout information, the width of the glyph, and — yes — the location, later in memory, of the bitmap data for the glyph. After this lookup table (plus a few other extras for Perso-Arabic shaping and localized case mapping), comes the 16- or 32-byte bitmaps for each glyph.
This lookup table takes up about 393 kilobytes of storage — but crucially, it gives us constant-time lookup into the giant blob of bitmap data. With O(1) complexity, we now know where to look for a glyph's bitmap data, and how many bytes long it is. This lets us pack the bitmaps densely, with no gaps and no wasted space on unassigned code points.
This more than makes up for the 393 kilobyte hit.
Plus, with this information, we know a lot more about the glyphs! Take a look in the right column above, under "code point 0020". This is the classic ASCII space character, and the metadata tells us that it represents a valid point for word wrapping, that it’s got a width of 8 pixels, it’s whitespace, and it has no left-to-right or right-to-left affinity. This makes sense: a space in Hebrew text is the same as a space in English text. You can use it forward or backward; there aren’t any special leftward-facing spaces.
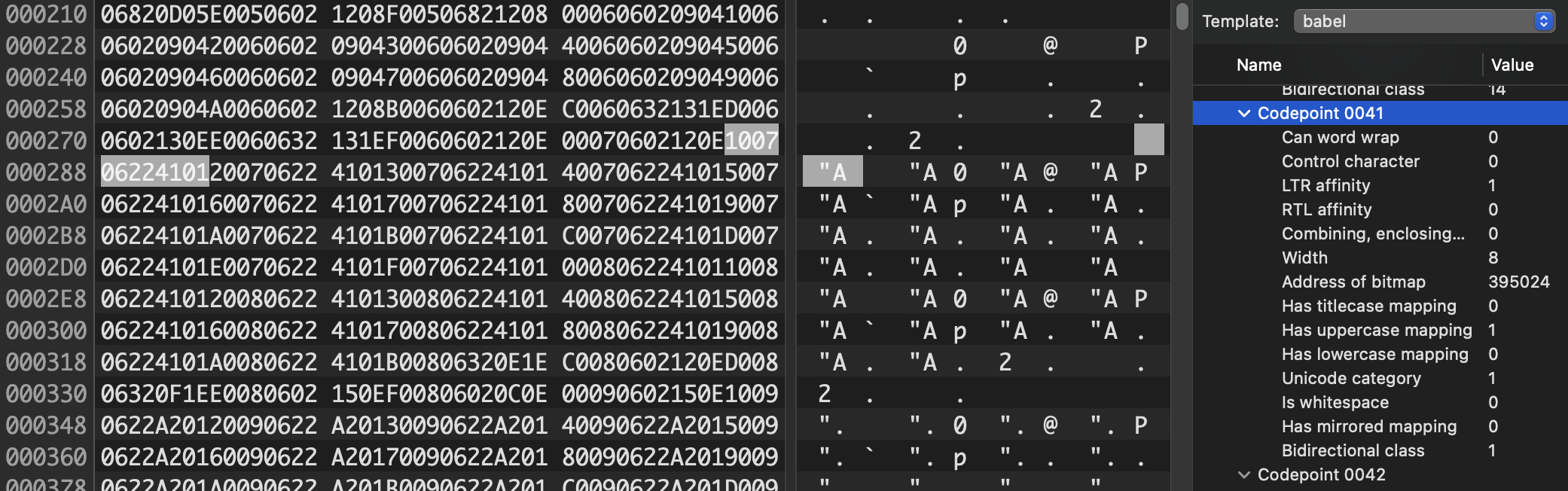
But here, for code point 0041( the ASCII ‘A’), we see different properties: you can’t word wrap on it, obviously, since it could appear at the beginning of a word, but it also has a distinct left-to-right affinity: if we were to mention “Apple Inc.” in the middle of a run of right-to-left Arabic text, we’d have to change the layout direction immediately (otherwise it would appear as “elppA” which I’m pretty sure is the name of an IKEA bookshelf that I once had in my dorm room).
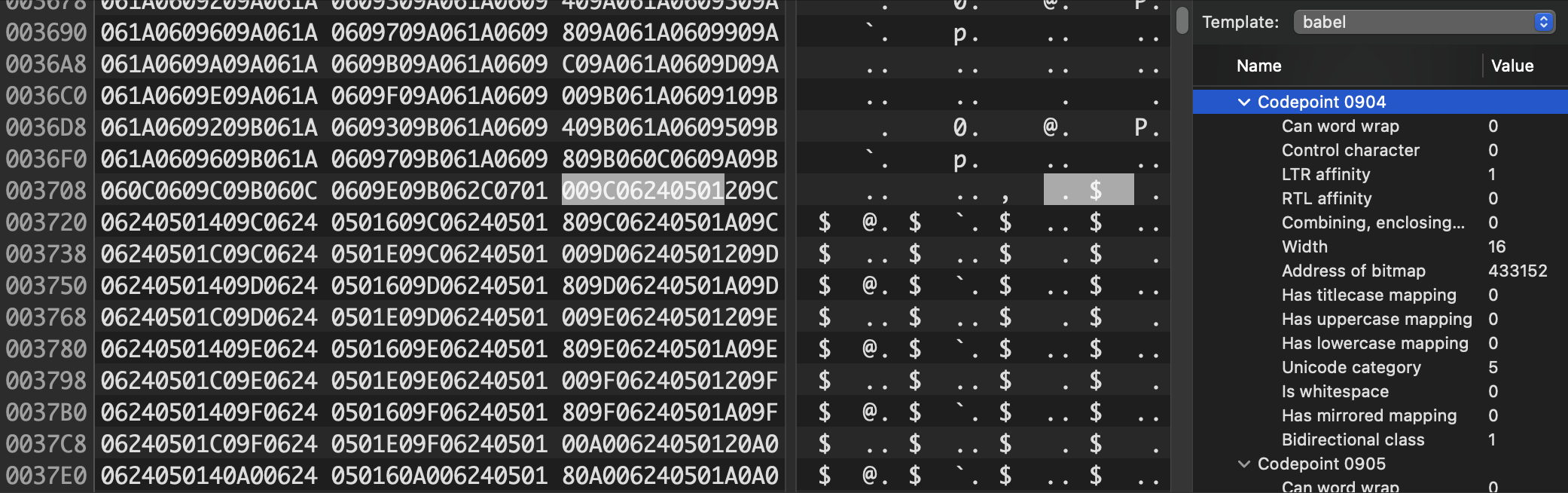
Meanwhile, our Devanagari ‘A’ at code point 0904 has similar directional affinity, but a width of 16 pixels instead of 8. Other glyphs, like those in the Hebrew block, would have a different directional affinity. The metadata would also tell us about some characters that mirror in right-to-left text runs (parentheses need to flip around, for example), whether a mark is a combining or enclosing mark, like the ´ in José or the "NO" symbol over this snowman (indicating, of course, that no snowmen are allowed): ☃⃠.
But I digress. The point is that with this information, we know all the relevant details about the glyph, including where to look for the bitmap data, how much bitmap data is stored there, and how many pixels to advance after drawing the character. Which, for Unifont, is always 8 or 16 pixels.
But here’s the thing…
In theory, I could have made the “width” property a single bit. Unifont is monospace, except for those big double-wide glyphs, and a boolean indicating whether the glyph is double-wide would have been enough to capture the size of the bitmap. Still, back in 2019 when I was coding Babel, I made the width field five bits long, which means it’s able to express any value from 0 to 31 pixels. In a comment defending this choice, I wrote that I was doing it “in case a variable width font becomes a thing.”

Fast forward to four years later, and a variable-width font has become a thing. In particular, the Ark font by designer TakWolf aims to be a pan-CJK pixel font at three sizes — but it also includes a healthy selection of proportional-width glyphs from the ASCII, Latin, Greek and Cyrillic blocks. To make a long story short less long, I did some hacks and started using that four-year-old width field to store proportional spacing data. With an export of Ark’s library of proportional width glyphs to Unifont's preferred hex format, it basically “just worked”.

Like I said a couple of weeks ago, I’ve been reading Cormac McCarthy’s “Blood Meridian” on one of the latest prototypes, and this proportional width typography has been an unmitigated joy to read (even if the book itself is a violent fever dream of breathtaking depravity).
For a less blood-soaked excerpt, here’s a comparison of the first page of The Great Gatsby, rendered with the old Unifont glyphs on the left and the new Ark glyphs on the right:

I, for one, know which one I want to read. And the best part is, I think we can have this feature without sacrificing on global coverage! I see no reason why we can’t import the Ark glyphs for English and Western European languages, while falling back on Unifont’s 100% coverage of the basic multilingual plane for the rest of the world. In fact, with the ESP32-S3 version of the book (the one I’m submitting for the Hackaday prize) we may be able to go even further. With eight megabytes of Flash memory, right there on the ESP32-S3 module, I think we can fit the basic AND supplemental multilingual planes onto the device — at a lower cost, AND with fewer part placements.
Anyway: if you made it this far, congratulations! I know it was something of an epic read, but this pair of posts represents the fullest possible accounting of the importance of the Open Book's universal language support, and the technical details of how we implement it on a resource constrained microcontroller. For more information, you can check out the Babel repository on GitHub, where you can download babel.bin along with an Arduino library that will let you add this universal language support to your own microcontroller-oriented projects. Ark's proportional-width glyphs aren't in there yet, but I hope to work on adding them in the next few weeks. They make the book even more of a joy to use, and I can't wait to share that experience with more people.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
Very important information
Are you sure? yes | no