 Tim
TimTraining dataset
Since the capabilities of the target platform are somewhat limited, I elected to create a simplified synthetic dataset for training. I chose 1x32x32 greyscale as target resolution for the images, as this fits into 1kb footprint. The resolution can be increased later, and we can obviously also use a fancier looking die image at a later time.
I need labeled images showing die-rolls with 1-6 pips. There should also be some variation, because otherwise using generative AI is quite pointless.
I used GPT4 to generate a Python program to generate images of dice and later refined it iteratively with copilot in vscode. While all the attention is on GPT, copilot chat got impressively useful in the mean time. It's much easier to interact with specific parts of your code, while this is a hazzle in GPT4.
Images are created in 128x128 and then downscaled to 32x32 to introduce some antiailiasing. The die images are rotated by an arbitraty angle to introduce variation. It should be noted that rotation of the dies requires them to be scaled down, so they are not clipped. This will introduce also a variation in scaling to the dataset.
Example outputs are shown below.
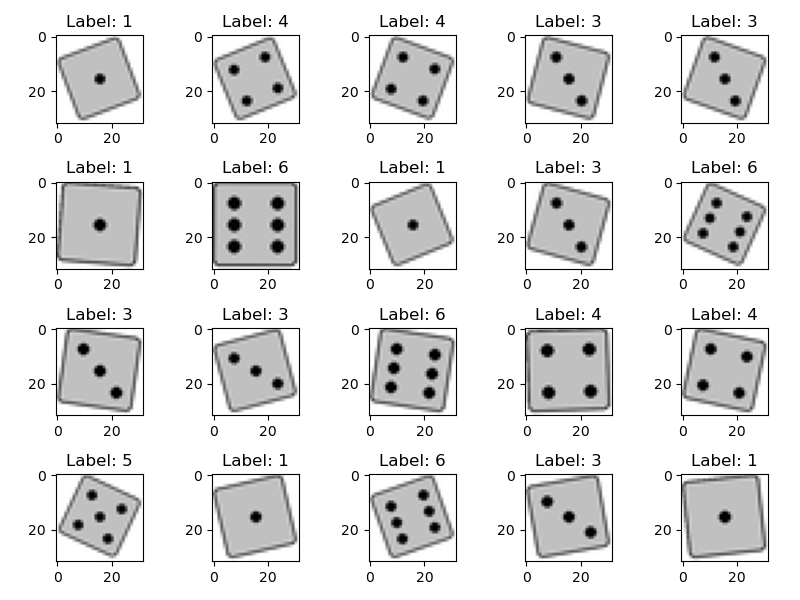
I will push the code to github later.
Evaluation Model CNN
As a first test, I trained a small CNN using PyTorch that can later be used to automatically evaluate the output of the generative AI model. I did not specifically try to optimize the CNN architecture. In first tests, it was able to identify the labels with 100% accuracy on a 4000/1000 training/test data set. Obviously too easy, as there is limited variation in the dataset.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(in_features=16*16*16, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=6)
def forward(self, x):
x = self.conv1(x)
x = nn.functional.relu(x)
x = self.conv2(x)
x = nn.functional.relu(x)
x = nn.functional.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
output = nn.functional.log_softmax(x, dim=1)
return output
To enable the network to also identify lower quality images, I augmented the dataset by introducing some distortion to the test images
- The center of the die is randomly shifted in X/Y, potentially leading to only a part of the die being visible
- Images are blurred with 50% probability and varying extend
- Various levels of noise are added, again on a randomly chosen 50% subset.
The image below shows examples from the augmented dataset to train the evaluation model. Obviously we are not going to use this for training of the GenAI, as we would like to generate clean images.

The accuracy on the test dataset dropped to 98% now (984/1000). The 25 images with the highest loss are shown below. Obvsiously, adding a lot of noise and blur makes it difficult to detect the number of pips. But there are also some suprising outliers.

Ok, obviously I spent quite some time fiddling around with the settings, but this looks like an acceptable starting point now. On to the next step.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.