In this log entry I present some benchmarks regarding the inference speed of the movenet model I use for human pose estimation. The benchmarks are carried out on the backend system, comprising a i5 4690K four-core CPU and GTX1660 GPU with 6GB memory.
To download the model from www.kaggle.com, search for 'movenet' in the models section, select the 'tensorflow 2' tab, select 'single-pose-thunder' from the variation drop-down menu. It offers version 4 of the pretrained model. Download the 'saved_model.pb' file and the complete 'variables' directory and place everything in a local directory.
For the benchmark I use the following code. It measures the time of the first inference, then it runs 100 inferences without measurement for warmup. The measurement is done for 2000 inferences with different random input images.
Code snippet 1: Inference benchmark
import numpy as np
import tensorflow as tf
from time import monotonic
modelPath = '/home/pi/movenet_single_pose_thunder_4'
model = tf.saved_model.load(modelPath)
movenet = model.signatures['serving_default']
# create 8-bit range random input
input = np.random.rand(1, 256, 256, 3) * 255
input = tf.cast(input, dtype=tf.int32)
start = monotonic()
out = movenet(input)
print(f'first inference time: {(monotonic() - start)}')
nWarmup = 100
for i in range(nWarmup):
out = movenet(input)
print('starting measurement')
nMeasure = 2000
times = []
for i in range(nMeasure):
input = np.random.rand(1, 256, 256, 3) * 255
input = tf.cast(input, dtype=tf.int32)
start = monotonic()
out = movenet(input)
times.append(monotonic() - start)
print(f'mean inference time: {np.mean(times)}')
print(f'min inference time: {np.min(times)}')
print(f'max inference time: {np.max(times)}')
print(f'standard deviation: {np.std(times)}')
The results can be found in the first row ('plain tensorflow') of table 1. The average inference time of 23.4ms is quite disappointing, given that I could measure 27ms already on a RaspberryPi 4 with a Google Coral AI accelerator.
Table 1: Benchmark results
| first | mean | min | max | std | |
| plain tensorflow | 2.03 s | 23.4 ms | 8.7 ms | 25.5 ms | 2.9 ms |
| tensor rt | 419 ms | 5.6 ms | 3.9 ms | 15.4 ms | 0.51 ms |
| tensor rt + cpu_affinity | 407 ms | 3.8 ms | 3.7 ms | 3.9 ms | 23 µs |
In order to accelerate the inference, I used nvidias TensorRT inference optimization. The following code creates an optimized version of the model. With this optimized code, I obtained the values in the second row ('tensor rt') of table 1. The average inference time was reduced approximately by a factor of four. The optimization itself took 82 seconds.
Code snippet 2: TensorRT conversion
import numpy as np
import tensorflow as tf
from tensorflow.python.compiler.tensorrt import trt_convert as trt
from time import monotonic
start = monotonic()
inputPath = '/home/pi/movenet_single_pose_thunder_4'
conversion_params = trt.TrtConversionParams(
precision_mode=trt.TrtPrecisionMode.FP32)
converter = trt.TrtGraphConverterV2(input_saved_model_dir=inputPath,
conversion_params=conversion_params)
converter.convert()
def input_fn():
inp = np.random.random_sample([1, 256, 256, 3]) * 255
yield [tf.cast(inp, dtype=tf.int32)]
converter.build(input_fn=input_fn)
outputPath = '/home/pi/movenet_single_pose_thunder_4_tensorrt_benchmark'
converter.save(outputPath)
print(f'processing time: {monotonic() - start}')
I could reduce the average inference time further by adding the following lines to the beginning of the benchmarking script. They assign the python process to a specific core of the four-core CPU. With this change, I obtained the values in the third row ('tensor rt + cpu_affinity') of table 1.
Code snippet 3: CPU affinity
import psutil osProcess = psutil.Process() osProcess.cpu_affinity([2])
During the measurement 'tensor rt + cpu_affinity', htop shows that actually only one CPU core is used.

nvidia-smi shows that the GPU runs at half of its maximum power usage and the fan is completely off.
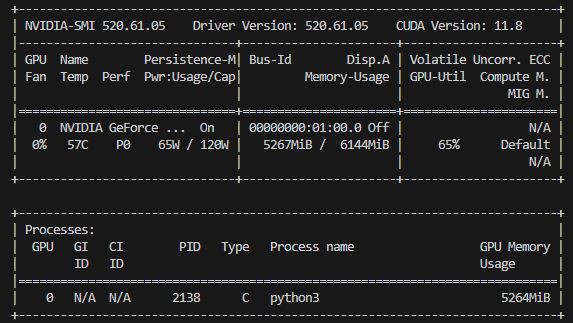
The results of the accelerated configuration are really satisfactory. Not only is the average inference time (3.8ms) approximately a factor of seven lower than with the Google Coral AI accelerator (27ms, RaspberryPi4), but here, the computation precision is higher (float32 instead of int8), yielding better pose estimation results (not shown here).
I also measured the inference time in the lalelu_drums application. The following graph shows the results for 1000 consecutive inferences performed for live camera images at a framerate of 100 frames per second.

It can be seen that in this environment the inference time is larger again (5ms ...6.6ms) and that there are random switches between fast and slow phases. Currently I do not have an explanation for any of the two observations. I did not yet experiment with the isolcpu setting, that I used in the RaspberryPi4 setup, though.
However, I am very happy, that I can achieve 100fps live human pose estimation with floating point precision and more-or-less realtime performance. This should be a good basis for building a low-latency musical instrument.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.