 Jon Nordby
Jon NordbySummary/TLDR
This looks to just-barely-doable on the chosen microcontroller (4 kB RAM and 32 kB FLASH).
Expected RAM usage is 0.5 kB to 3.0 kB, and FLASH between 10 kB to 32 kB FLASH.
There are accelerometers available that add 20 to 30 cents USD to the Bill of Materials.
Random Forest on time-domain features can do a good job at Activity Recognition.
The open-source library emlearn has efficient Random Forest implementation for microcontrollers.
Applications of Activity Recognition
The most common sub-task for Activity Recognition using accelerometers is Human Activity Recognition (HAR). It can be used for Activities of Daily Living (ADL) recognition such as walking, sitting/standing, running, biking etc. This is now a standard feature on fitness watches and smartphones etc.
But there are ranges of other use-cases that are more specialized. For example:
- Tracking sleep quality (calm vs restless motion during sleep)
- Detecting exercise type counting repetitions
- Tracking activities of free-roaming domestic animals
- Fall detection etc as alerting system in elderly care
And many, many more. So this would be a good task to be able to do.
Ultralow cost accelerometers
To have a sub 1 USD sensor that can perform this task, we naturally need a very low cost accelerometer.
Looking at LCSC (in January 2024), we can find:
- Silan SC7A20 0.18 USD @ 1k
- ST LIS2DH12 0.26 USD @ 1k
- ST LIS3DH 0.26 USD @ 1k
- ST LIS2DW12 0.29 @ 1k
The Silan SC7A20 chip is said to be a clone of LIS2DH.
So there looks to be several options in the 20-30 cent USD range.
Combined with a 20 cent microcontroller, we are still below 50% of our 1 dollar budget.
Resource constraints
It seems that our project will have a 32-bit microcontroller with around 4 kB RAM and 32 kB FLASH (such as the Puya PY32F003x6). This sets the constraints that our entire firmware needs to fit inside. The firmware needs to collect data from the sensors, process the sensor data, run the Machine Learning model, and then transmit (or store) the output data. Would like to use under 50% of RAM and FLASH for buffers and for model combined, so under 2 kB RAM and under 16 kB FLASH.
Overall system architecture
We are considering an ML architecture where accelerometer samples are collected into fixed-length windows (typically a few seconds long) that are classified independently. Simple features are extracted from each of the windows, and a Random Forest is used for classification. The entire flow is illustrated in the following image, which is from A systematic review of smartphone-based human activity recognition methods for health research.
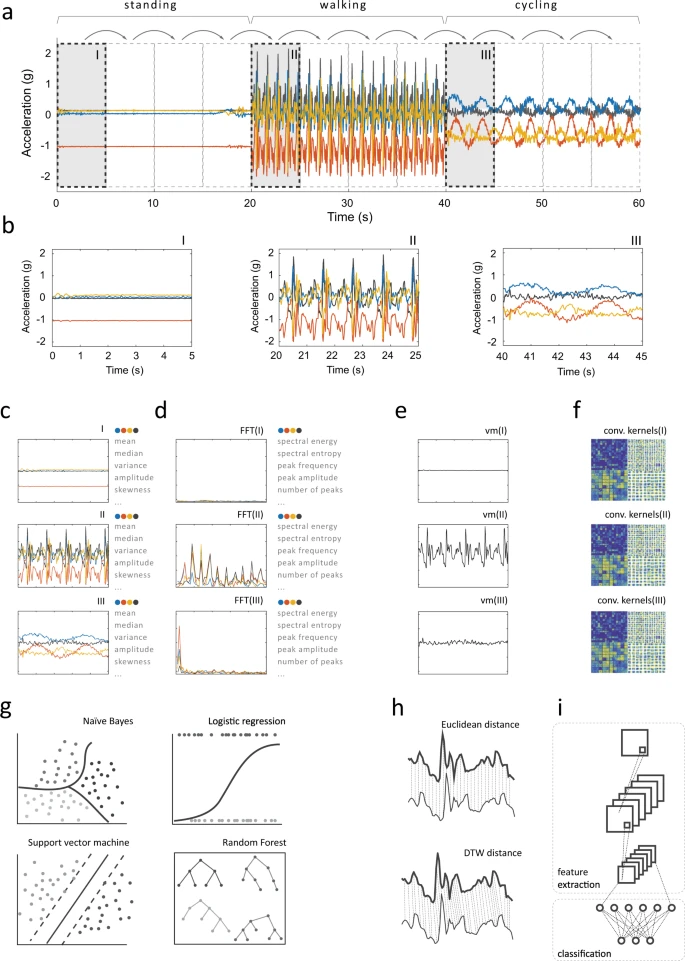
This kind of architecture was used for in the paper Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition? The paper shows that it is possible to perform similarly to a deep-learning approach, but with resource usage that are 10x to 100x better. They were able to run on Cortex-M3, Cortex-M4F and Cortex M7 microcontrollers with at least 96 kB RAM and 512 kB FLASH. But we need to fit into 5% of that resource budget...
RAM needs for data buffers
The input buffers, intermediate buffers, tends to take up a considerable amount of RAM. So an appropriate tradeoff between sampling rate, precision (bit width) and length (in time) needs to be found. Because we are continiously sampling and also processing the data on-the-run, double-buffering may be needed. In the following table, we can see the RAM usage for input buffers to hold the sensor data from an accelerometer. The first two configurations were used in the previously mentioned paper:
| samples | size | percent | |||||
|---|---|---|---|---|---|---|---|
| buffers | channels | bits | samplerate | duration | |||
| 2.00 | 3 | 16 | 100 | 1.28 | 128 | 1536 | 37.5% |
| 2.56 | 256 | 3072 | 75.0% | ||||
| 8 | 50 | 1.28 | 64 | 384 | 9.4% | ||
| 2.56 | 128 | 768 | 18.8% | ||||
| 1.25 | 3 | 8 | 50 | 2.56 | 128 | 480 | 11.7% |
16 bit is the typical full range of accelerometers, so it preserves all the data. It may be possible to reduce this down to 8 bit with sacrificing much performance. This can be done by scaling the data linearly, or implementing a non-linear transform such as square-root or logarithm to reduce the range of values needed.
Using 50 Hz sampling rate would also be very beneficial to reduce RAM usage. Assuming that feature processing is quite fast, it should also be possible to not use full double-buffering. It may also be possible to keep a buffer of computed features (much smaller in size) for the windows and classify them together. This would allow reducing the window size, but maintain information from a similar amount of time in order to keep performance up.
So it seems feasible to find a configuration under 2 kB RAM that has good performance.
Feature extraction
In the previously referenced paper, they used 9 features. These compute simple statistics directly on each window.
No FFT or similar heavy processing is used. This should have a negligible RAM (under 256 bytes) and FLASH usage (under 5kB).
Random Forest classifier, FLASH requirements
The previously mentioned paper tested using 10-100 trees, with a max_depth of 9. The authors found that more than 50 trees gave a marginal improvements in F1 score. They reported 10 trees used 10kB FLASH, and 50 trees to be around 50 kB FLASH.
However, it does not appear that they did any hyperparameter optimization to find smaller models. Therefore, I forked their git repository with the experiments and added my own tuning. I varied by the depth of the trees and the number of features per tree, in order to see if a smaller amount of trees. Both reducing number of trees and the depth helps to reduce model size. The code can be found at https://github.com/jonnor/feature-on-board-activities, and results are in the following image:
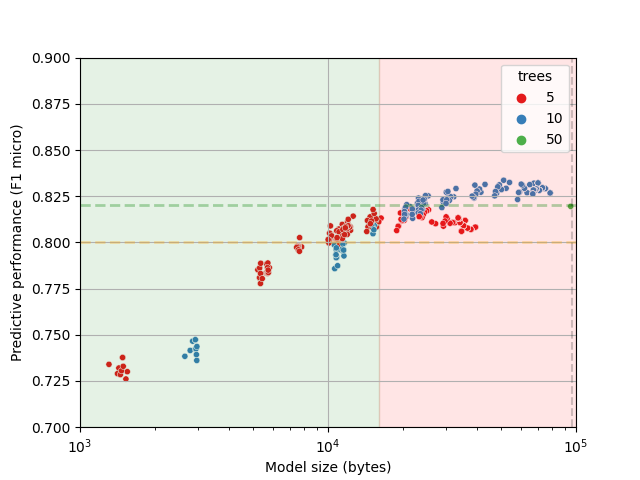
The original performance (50 trees, max_depth=9) is marked with a green dot (on the right side). We can see that 5 trees can just barely hit the same performance levels, and that 10 trees is able to improve the performance. And that the model size can be 4-10x smaller with no or marginal degradation in performance.
The size estimates in the plot are for the "loadable" inference strategy in emlearn. Benchmarks show that when using the "inline" inference strategy with 8-bit integers, then model size is approximately half. So the models that take 20 kB in the plot should in practice take around 10 kB.
At 10 kB these models are able to match the performance of the untuned model (which matched the deep-learning baselines), and fit in our 16 kB FLASH budget.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.