 kasik
kasikIt seems I haven't been here for a while, fear not - the project continues! Due to some other projects, I was forced to upgrade my Linux distribution, thus most of the packages got updated as well. I must admit, It took me an hour or two to fix the project due to changes in the libs. Now I am using Keras version 3.2.1.
I wanted to come back to the topic of overfitting, which can cause many troubles when working on a model. Very often, while observing the training progress - we may see a beautiful curve of training and accuracy that reaches 1 very quickly and stays there. At the same time - the training loss gets very close to 0. Such graphs may lead to a false impression that we have created an excellent neural network.
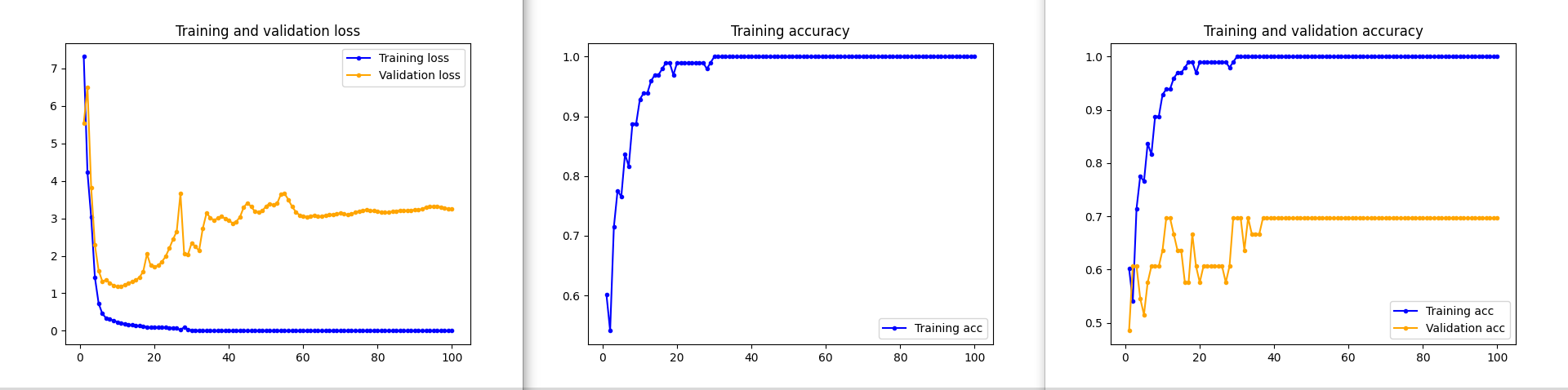
Unfortunately that is too good to be true. If we look at the validation graphs instead, it doesn't seem so great anymore - the accuracy and loss lag way behind and achieve worse performance.
What actually happens is that the neural network becomes too specialized, learns the training set too well, that it fails to generalize on the unseen data.
And that is overfitting in a nutshell. There are various ways to fight that.
1. Use more data!
Sounds easy enough yet not always feasible. It shouldn't come as a surprise that there are ways to overcome that as well, such as data augmentation (log post coming soon) or even transfer learning, where a pretrained model is used (log post coming soon).
As a note - random shuffling the data order has a positive effect as well.
2. Model ensembles
Sounds strange, doesn't it? Model ensembles means using several neural networks with different architectures. However, it is quite complex and computationally expensive.
3. Regularization
I used this term already a few times - this is a set of techniques that penalizes the complexity of the model. Its goal is to add some stochasticity during training. It can mean for example adding some extra terms during the loss calculation or early stopping - which means stopping learning process when the validation loss doesn't decrease anymore.
A technique that I find interesting is a dropout - where the activations from certain neurons are set to 0. Interesting enough - this can be applied to neurons in fully connected layers or convolution layers - where a full feature map is dropped. This means that temporarily new architectures are created out of the parent network. The nodes are dropped by a dropout probability of p (for the hidden layers, the greater the drop probability the more sparse the model, where 0.5 is the most optimised probability). Note that this differs with every forward pass - meaning with each forward pass it is calculated which nodes to drop. With dropout we force the neural network to learn more robust features and not to rely on specific clues. As an extra note - dropout is applied only during training and not during predictions.
On the graphs below you can se the effect of adding a dropout: - the the validation loss follows the curve of training loss; the training accuracy doesn't reach immediately 1 and validation accuracy follows the training one.
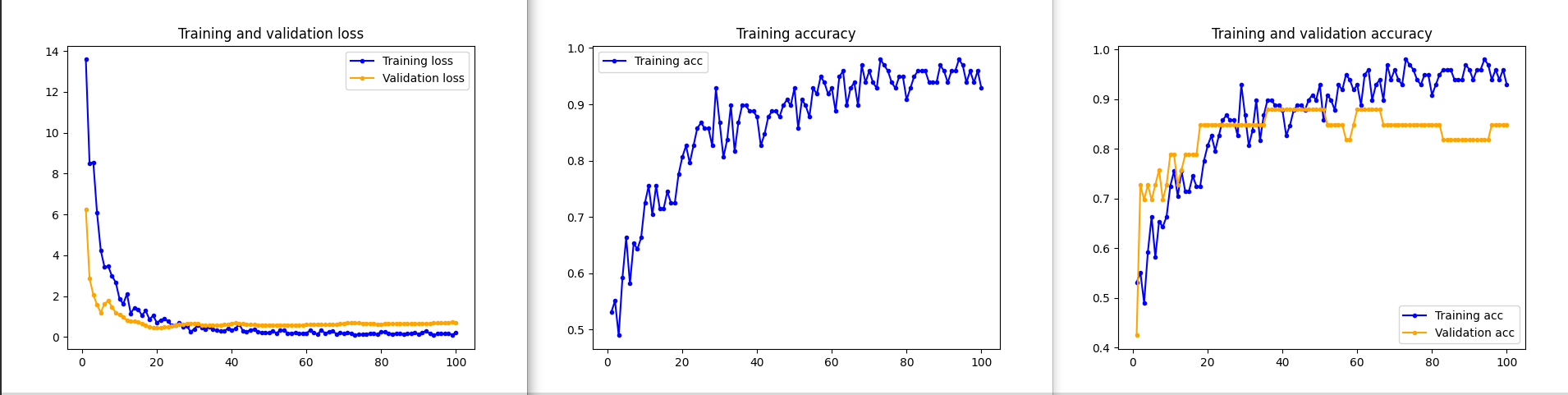
In my project I use dropout on fully connected layers, I will further increase the dataset, use data augmentation, try out transfer learning.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.