 Shakhizat
Shakhizat-
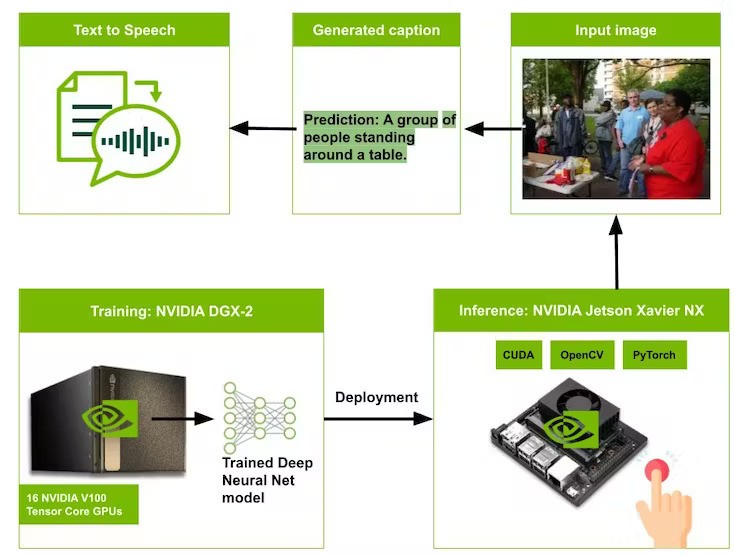
1Image Captioning Model deployment pipeline
We used the popular Microsoft COCO 2014 (COCO) benchmark dataset to train the ExpansionNet v2 image captioning model. The dataset consisted of 123, 287 images, with each image having five human-annotated captions, resulting in a total of over 600, 000 image-text pairs. We split the dataset into training (113, 287 images), validation (5, 000 images), and test (5, 000 images) sets, using the Karpathy splitting strategy for offline evaluation. To generate captions in Kazakh, we translated the original English captions using the freely available Google Translate service.
![]()
To train the model for Kazakh captions, we followed the model architecture defined in the original work of the ExpansioNet v2. The pre-trained Swin Transformer was used as a backbone network to generate visual features from the input images. The model was trained on four V100 graphics processing units (GPUs) in Nvidia DGX-2 server.
Finally, the image captioning model, ExpansionNet v2, was deployed on the Nvidia Jetson Xavier NX board. The camera was triggered by pressing the push button to capture an RGB image with a resolution of 640 × 480 pixels. Then, the captured image was resized to 384 × 384 and passed to the ExpansionNet v2 model to generate a caption. Next, the generated caption text was converted into audio, using a text-to-speech model. In our research study, we utilized the KazakhTTS model to convert Kazakh text to speech. Finally, the generated audio was played through the user’s headphones, making it possible for individuals who are blind or visually impaired to comprehend what is in front of them.
-
2ONNX overview
ONNX is an open format for machine learning and deep learning models. It allows you to convert deep learning and machine learning models from different frameworks such as TensorFlow, PyTorch, MATLAB, Caffe, and Keras to a single format.
The workflow consists of the following steps:
- Convert the regular PyTorch model file to the ONNX format. The ONNX conversion script is available here.
- Create a TensorRT engine using trtexec utility
trtexec --onnx=./model.onnx --saveEngine=./model_fp32.engine --workspace=200
- Run inference from the TensorRT engine.
-
3Inference Optimization using TensorRT
TensorRT is a high-performance deep learning inference engine developed by NVIDIA. It optimizes neural network models and generates highly optimized inference engines that can run on NVIDIA GPUs. TensorRT uses a combination of static and dynamic optimizations to achieve high performance, including layer fusion, kernel auto-tuning, and precision calibration.
PyTorch, on the other hand, is a popular deep learning framework that is widely used for research and development. PyTorch provides a dynamic computational graph that allows users to define and modify their models on the fly, which makes it easy to experiment with different architectures and training methods.
![]()
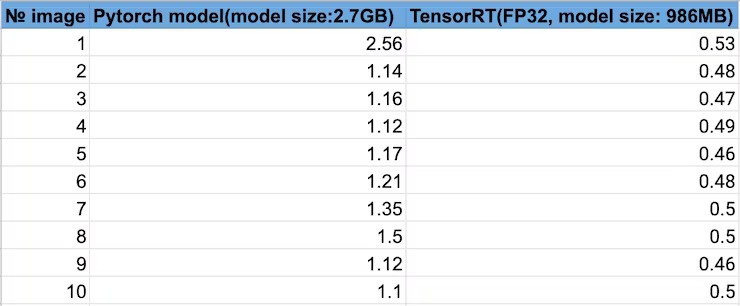
It appears that the TensorRT model is providing faster inference results compared to the PyTorch model. The TensorRT model is taking around 50% less time to process the images compared to the PyTorch model, even though it has a smaller file size.
In a nutshell, if speed and efficiency are your primary concerns, then TensorRT may be a better choice. This is fast enough for most real-time object detection applications.
During the inference process, you can check the current performance of the Nvidia Jetson boards using jetson-stats utility. You can monitor the resources that your models are using in real time and get maximum utilization out of your hardware.
-
4A real-world experiment with a human subject wearing the image captioning assistive device
This figure illustrates the real-world experiment of our image captioning assistive system, which comprised a camera, a single-board deep learning computer (Nvidia Jetson Xavier NX), a push button, and headphones.
![]()
The camera was connected to the single-board computer through a universal serial bus (USB), while the push button and headphones were connected to the general-purpose input/output (GPIO) pins and audio port of the single-board computer, respectively. The camera was secured to the user's forehead using adjustable straps, while the user carried the single-board computer (and a power bank) in a backpack and wore the headphones during operation.
-
5Conclusion and further improvements
Visually impaired and blind individuals face unique challenges in their daily lives, including the inability to independently access visual information. Image captioning technology has shown promise in providing assistance to this community.
In addition to the existing image captioning and text-to-speech technologies, we aim to incorporate Visual Question Answering (VQA) functionality into our assistive device for the visually impaired and blind. This will enable users to ask questions about the images and receive spoken answers.
To further optimize our deep learning model and improve its performance, we will perform quantization from FP32 to FP16 or INT8. This will reduce the memory footprint and computation time required for inference, making our assistive device more efficient.
If you are interested in our project, please consider adding a star to our repository on github. Thanks a lot!
I hope you found this research study useful and thanks for reading it. If you have any questions or feedback, leave a comment below. Stay tuned!
-
6Acknowledgements
- The implementation of the Image captioning model relies on ExpansioNet v2.
Image Captioning for the Visually Impaired People
This project aims to improve accessibility for visually impaired and blind people by developing a novel image captioning system.

Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.