Cassio Batista
Cassio BatistaAs stated by the World Health Organization (WHO) on its book [WHO Global Disability Action Plan 2014-2021], approximately 15% of the whole population of the globe has some kind of disability. This number really speaks volumes, since it reveals that in a population of 7.6 billion people, around one out of seven (1 billion people) is a disabled person. WHO also affirms that 80% of people with disabilities lived in sub-developed countries in 2013, which suggests that the disability condition is pretty much related to the economic situation of the country of residence.
It is well known that the automatic speech recognition (ASR) technology not only improves the human-computer interaction, making it easier for most people; but also acts as an assistive technology for both social and digital inclusion of specially people with upper-limb motor disability, who have all sort of difficulties at using their hands — or even cannot use them at all — to perform mainstream, day-to-day activities that seem trivial for non-disabled people.
Recently, companies have invested in speech recognition systems running on cloud platforms. Commercial devices such as Google Home and Amazon Echo then started to show up as personal assistants. Software-based virtual assistants also have become present on people's lives, such as Google Assistant and Apple's Siri. As Internet accesses continue to grow, these kind of services tend to become more and more common — at least to the ones who can afford.
However, despite some people's privacy concerns 1,2 (not everyone likes a device that is “listening” all the time, gathering audio data and sending to someone else's server), the devices still require a reasonably good Internet connection to provide a real-time speech interface for the users. Although the number of people with access to Internet is close to 3.4 billion today, according to ITU's website, approximately 54.21% of the world's population (4 bi) is still offline. Furthermore, as the disability condition is more frequent in sub-developed countries, it is likely that most people who are impaired might not be able to benefit from cloud services' advantages.
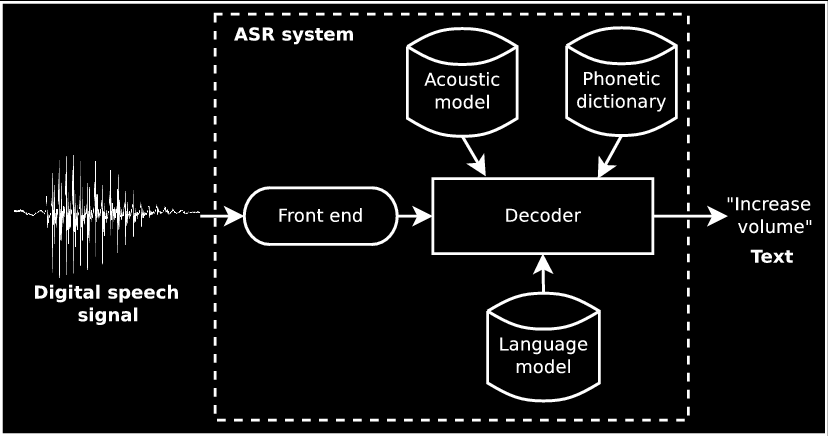
Therefore, this project aims at developing a low-cost, universal remote control system based on an embedded platform, the Next Thing Co.'s single board computer (SBC) called C.H.I.P., which was configured as a centralized hub at home environment in order to control some electronic devices. Since C.H.I.P. runs a Debian OS (Linux-based), the system is able to offline recognize speech in real time through the PocketSphinx package. As an alternative, PocketSphinx could be replaced by Google's android.speech API on Android-based OS, which would process speech signals and send just the recognized text to the hub via Bluetooth. The connection between the smartphone and the SBC would be handled by android.bluetooth and BlueZ APIs, respectively. An overall schematic of the system is shown below as a “flowchart”.
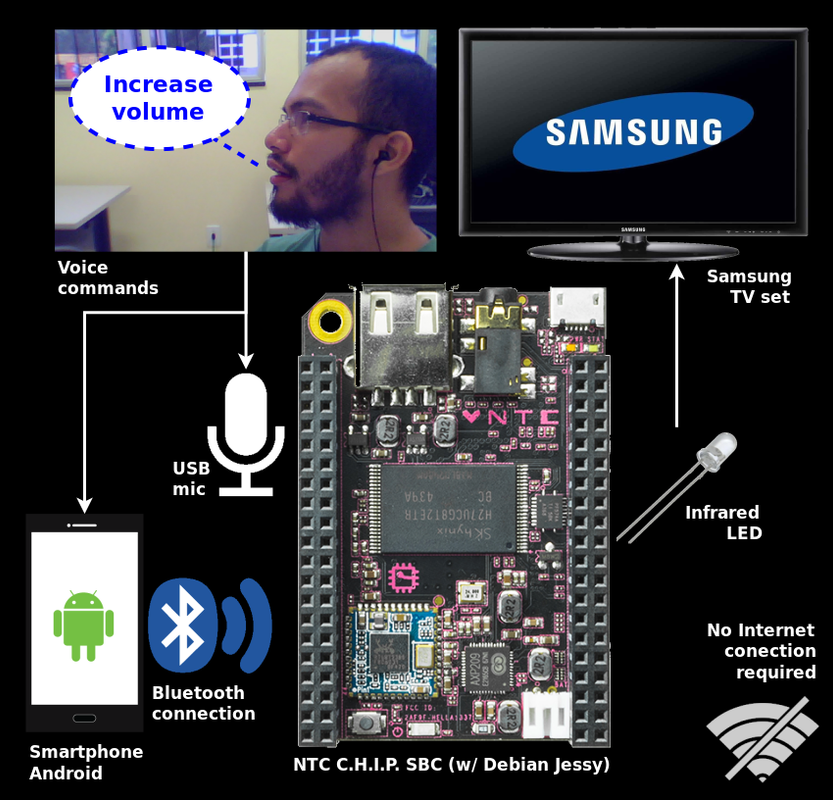
The system could then provide an alternative interface of control for people with upper-limb motor disabilities. This is expected to give them more independence and autonomy, since traditional remote control devices impose a giant barrier by forcing the use of hands and fingers by the user. It's important to note that both software and hardware used and built to create the proposed system are mostly open-source and open-hardware. PocketSphinx is a speech recognition toolkit freely available under the Berkeley Software Distribution (BSD) 2-Clause3,4. Next Thing's C.H.I.P. follows the Creative Commons Attribution-ShareAlike (CC BY-SA) license5,6, while Debian OS and BlueZ Bluetooth stack are both open-source under the GNU Public License (GPL)7,8. About Android APIs licenses, I'm not sure, but I think it is up to the app developer. My codes are being released on GitHub anyway, so I'll publish them under an open license as well :)...
Read more »





 KARTHIK RAVI
KARTHIK RAVI
 Patrick
Patrick