-
Future Work
05/25/2023 at 18:15 • 0 commentsAs mentioned in the High Level Design Decisions log, we identified two fundamental features for a sign language interpreter:
- Two hands and arms, with full control of all degrees of freedom, to closely emulate human arms.
- A robust voice detection system, which would be constantly detecting audio.
We have implemented scaled-down versions of both features:
- One hand, with two degrees of freedom in each digit and one degree of freedom in the wrist.
- A voice detection system capable of capturing three seconds of audio.
For our product to be useful as a sign-language interpreter, we would need to enhance each of the features that we developed.
On the mechanical side, we would need to improve the design of our robotic hand. Currently, the robot consists of only one hand with two degrees of freedom in each digit and no motion in the wrist. Ideally, the robot would have two separate arms with full forearm control to form more complex signs. As well, the wrists of the robot would need to have full rotation and bending motion in all directions. The fingers of our robot can only move side-to-side and bend and extend. There is no motion in the knuckles of our hand. The robot would require an additional degree of freedom in the knuckles to accurately form more signs.
Solving the mechanical limitations mentioned above would require our team to redesign the robotic hand completely. We used open-source files to 3D print our mechanical hand instead of completing the mechanical design ourselves, which would have proved difficult, time-consuming, and outside the scope of this project. Simply designing the mechanics of a robust robotic arm configuration could easily become a semester or year-long project, especially given our lack of mechanical design experience and training.
For the voice detection system, we would need to be constantly detecting audio while the system is operational. Currently, we record audio for 3 seconds and then devote resources to processing and recognizing the audio. Our system takes about 5-10 seconds to process and detect 3 seconds worth of audio, so steps would have to be taken to speed up this process. As well, our system would need to record and detect audio simultaneously, which is currently not possible.
Further, we could improve audio filtering from the existing filters built into the microphone. This could be done by utilizing two or more microphone arrays that can be used to reduce background noise and focus solely on the closest speaker.
Finally, a fully robust sign language interpreter robot would require a much larger vocabulary. Our current design only implements 24 letters of the alphabet. To improve our design, we would need to make significant changes to our robot’s vocabulary to accommodate full words, phrases, and grammar in ASL.
If all the changes specified above could be made, the design could still be further improved by adding the capacity for detecting languages other than English and translating to sign languages other than ASL.
-
Choosing a Speech Recognition Model
05/25/2023 at 17:54 • 0 commentsDuring the development of our natural language processing (NLP) block, we researched and tested several different speech recognition libraries. We evaluated the libraries based on the following criteria:
- compatibility in programming languages used in our project
- accuracy of speech recognition
- open-source availability
- price
- offline/online availability
- size and speed of the library
We have researched the following libraries, listing both advantages and disadvantages of each one based on the factors mentioned above.
Kaldi is an open-source speech recognition software written in C++, which works on Windows, macOS, and Linux. Kaldi’s main feature over other speech recognition software is that it’s extendable and modular: The community provides tons of 3rd-party modules. Kaldi also supports deep neural networks and offers excellent documentation on its website. While the code is mainly written in C++, it is “wrapped” by Bash and Python scripts. Kaldi also provides a Python pre-built engine with English-trained models.
However, Kaldi has only a few open-source models available, most requiring a lot of space. Kaldi also has a long installation and build process. Part of that process requires creating configuration files for each transcription, which drastically increases the complexity of the NLP.
DeepSpeech is an open-source Speech-To-Text engine using a model trained by machine learning techniques based on the TensorFlow framework.
DeepSpeech takes a stream of audio as input and converts that stream of audio into a sequence of characters in the designated alphabet. Two basic steps make This conversion possible: First, the audio is converted into a sequence of probabilities over characters in the alphabet. Secondly, this sequence of probabilities is converted into a sequence of characters. DeepSpeech provides an "end-to-end" model, simplifying the speech recognition pipeline into a single model.
DeepSpeech, unfortunately, lacks documentation and features behind other competitors on this list.
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. Using such a large and diverse dataset improves robustness to accents, background noise, and technical language. Moreover, it enables transcription in multiple languages and translation from those languages into English.
Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
Unfortunately, Whisper models have a long runtime for embedded systems.
An end-to-end speech recognition engine that implements ASR.
Written in Python and licensed under the Apache 2.0 license. Supports unsupervised pre-training and multi-GPUs training either on the same or multiple machines. Built on the top of TensorFlow.
Has a large model available for both English and Chinese languages.
However, Athena does not support offline speech recognition, which is a requirement for our project.
Vosk is a speech recognition toolkit, which supports 20+ languages and dialects. Vosk works offline, even on lightweight devices - Raspberry Pi, Android, and iOS. Vosk has portable per-language models that are only 50Mb each and provide streaming API for the best user experience, as well as bindings for different programming languages. Vosk allows quick reconfiguration of vocabulary for best accuracy and supports speaker identification besides simple speech recognition.
Vosk also provides large documentation and technical support through GitHub and a large set of features.
We decided to use the Vosk speech recognition library due to its lightweight models and high accuracy in speech recognition.
-
High Level Design Decisions
05/25/2023 at 17:46 • 0 commentsAs a team, we considered many high-level design choices before building our current system. Building a sign language interpreter is an immensely complex task, which could not be perfected in the time we had. Operating under such tight time constraints, we realized early on that we would have to carefully choose which aspects of the project to complete and which to leave as future work. When deciding which areas of the project to focus on, we chose functionality that would serve as a strong foundation for further development. By focusing on basic functionality with this project, we will be able to return to this project later and easily improve upon our existing work.
A robust sign language interpreter robot would have two key features:
- Two hands and arms, with full control of all degrees of freedom to closely emulate human arms.
- A robust voice detection system, which would be constantly detecting audio.
It is worth noting that non-verbal communication is just as, if not more important in sign language as it is in spoken languages. Facial expression and body language are difficult to emulate accurately in robotics, requiring much more time, research, and resources than were available to our team.
As the foundation of our project, we chose to design and implement scaled-down versions of both those features:
- One hand, with two degrees of freedom in each digit and one degree of freedom in the wrist.
- A voice detection system capable of capturing three seconds of audio.
When deciding to implement those two features, we discussed many alternatives:
- Visually displaying detected words on a screen.
- Displaying a simulated hand or hands on a screen, which would sign the detected audio.
- Using a web server or the command line for the user to type in words or letters to be signed by the robotic hand.
- Using a web server with a list of available signs for the user to select words or letters to be signed by the robotic hand.
Each alternative design only captures one of the two key features of a sign language interpreter described above. For this reason, we split our project into two parts – the robotic hand and the audio detection.
-
Hand and Enclosure 3D Printing
05/25/2023 at 17:39 • 0 commentsThe robotic hand and primary enclosure for the Helping H.A.N.D.S. project are all 3D printed. There is a 3D-printed base at the bottom of the hand, which contains the servo connectors and the servo driver. Above the enclosure is the 3D-printed hand. The palm of the hand contains the servos used to control the movement of the fingers and thumb. Overlaid on top of the servo motors is a piece used to route tendons used to actuate the fingers. Finally, the fingers are connected to the top of the palm.
![]()
All the 3D printed parts used in our design are from the open-source Robot Nano Hand project. We printed the parts at the makerspaces at our university and on personal 3D printers using PLA filament. The inner palm piece had to be reprinted due to poor print quality the first time.
Due to printing the parts on multiple printers, there were some scaling issues. The servo motors did not initially fit inside the palm of the hand. As well, the inner palm piece did not align with the servos in the hand and needed to be cut. Even when pieces were printed to the correct scale, they still needed to be sanded to ensure smooth operation. Our team spent a combined 30+ hours sanding parts for this project. To reduce the amount of time spent sanding if we were to redo this project, we would slightly scale up all the prints to ensure the servo motors fit inside the palm.
-
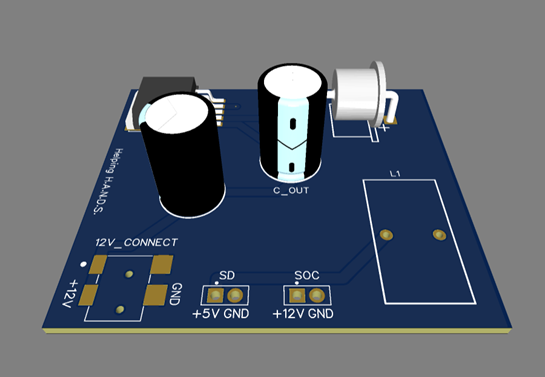
PCB Design
05/25/2023 at 17:30 • 0 commentsThe power management PCB was designed with EasyEDA and ordered from JLCPCB. Initially, we considered using Altium to design the PCB. However, the startup and learning time required to use Altium proved too long for the timeline of our project.
We designed, ordered, and implemented one iteration of our PCB. If we had more time, we would have completed a second iteration. However, the tight timeline of the project did not allow for this.
![]()
The purpose of the PCB is to provide regulated 12 Volt and 5 Volt outputs at a maximum of 3 Amperes. The servo driver and the ESP32 receive a 5 Volt input. The board also supplies a 12 Volt output due to a previous component, which is no longer included in the project. A 12 Volt regulated input is applied to the board through a barrel jack. To supply this power, a 12 Volt wall regulator is used to step down and convert the wall power to a DC signal. A buck converter is used within the PCB to step the 12 Volts down to 5 Volts. The PCB has 57.8 x 48.5 mm dimensions and is implemented on two layers.
As mentioned above, the PCB was ordered from JLCPCB for $21.71, of which $12.21 was shipping costs. Manufacturing of the PCB took two days, while shipping took seven days. Assembly took one day. Components for the PCB were either ordered from Digikey or sourced from our university's makerspaces and various student teams.
For PCB routing, we first used the auto-route feature from JLCPCB as a starting point, which we modified to eliminate as many 90-degree bends as possible. The trace width on our PCB is 1.5 mm, and the copper thickness is 1oz/ft2.
Power Analysis
Prior to designing the power management PCB, power analysis had to be done to understand the requirements of the board. The PCB is used to power the ESP32 as well as the servos. Both of those components require 5 Volts. However, the board also supplies 12 Volts. The largest current sink in our system is the servo bank. To understand the current draw of the servo driver, we tested actuating different numbers of servos at different speeds and noting the maximum values. During nominal operation, not all the servos will be moving at once, and they will be moving at a slower, steady pace. However, the servos will be under load from the hand. The estimated nominal current draw should not exceed 1 Ampere. When testing, the maximum current draw was 2 Amperes when all servos actuated simultaneously at maximum speed.
According to the above analysis, the PCB was designed for a system operating at a nominal 2 Amperes. To ensure our system is robust, an FoS of 1.5 was included. This means that all of our components were selected with a maximum current rating of at least 3 Amperes.
PCB Trace Width and Power Dissipation
The trace width for the power management PCB has to be able to withstand 3 Amperes. A trace width calculator was used to calculate the width for a 1 oz/ft2 copper thickness based on the 3 Ampere capacity. The calculator gave a result of 1.37 mm, and 1.5 mm was used in our design, giving an FoS of 1.1.
Power dissipation was also a factor in designing the PCB. The buck converter steps down 12 Volts to 5 Volts at a maximum nominal current of 2 Amperes. Therefore, the maximum nominal power dissipation is given by the equation below:
We chose a buck converter with thermal shutdown and current limit protection to dissipate this amount of power safely.
As well, the PCB has one via. A via calculator was used to verify the voltage drop and power loss in the via. Our via has a diameter of 0.8mm, with a length of 1.6 mm (the PCB's thickness). With a plating thickness of 1 oz/ft2, the voltage drop is 0.000993 Volts, and the power loss is 0.00298 Watts.
Helping H.A.N.D.S.
We are Electrical Engineering students who built and programmed a robotic hand to translate spoken language into ASL fingerspelling.