 lion mclionhead
lion mclionheadContinuation of a previous effort to track animals from the truck.
https://hackaday.io/project/183329-tracking-animals-on-arm-processors
This time, a full jetson nano is used.
Key differences between this & https://hackaday.io/project/162944-auto-tracking-camera
It has to be more portable by not supplying its own power.
It controls pan only.
It has to differentiate 1 animal from many other animals. This is being attempted by combining face recognition with body detection.
An offline video cropper using a 360 cam would be simpler but wouldn't match the picture quality of a full frame camera.
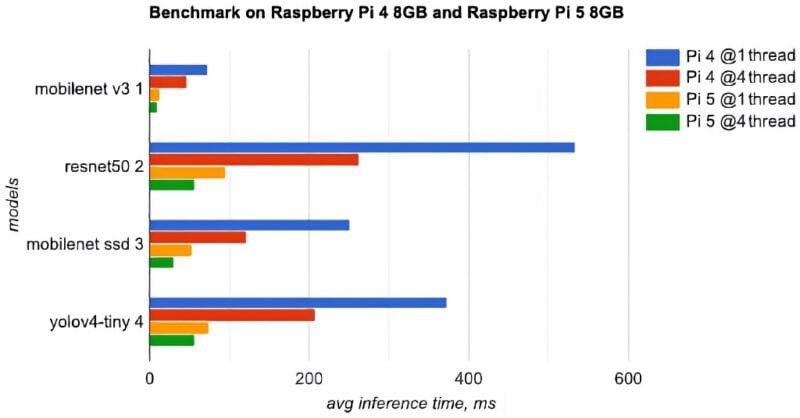
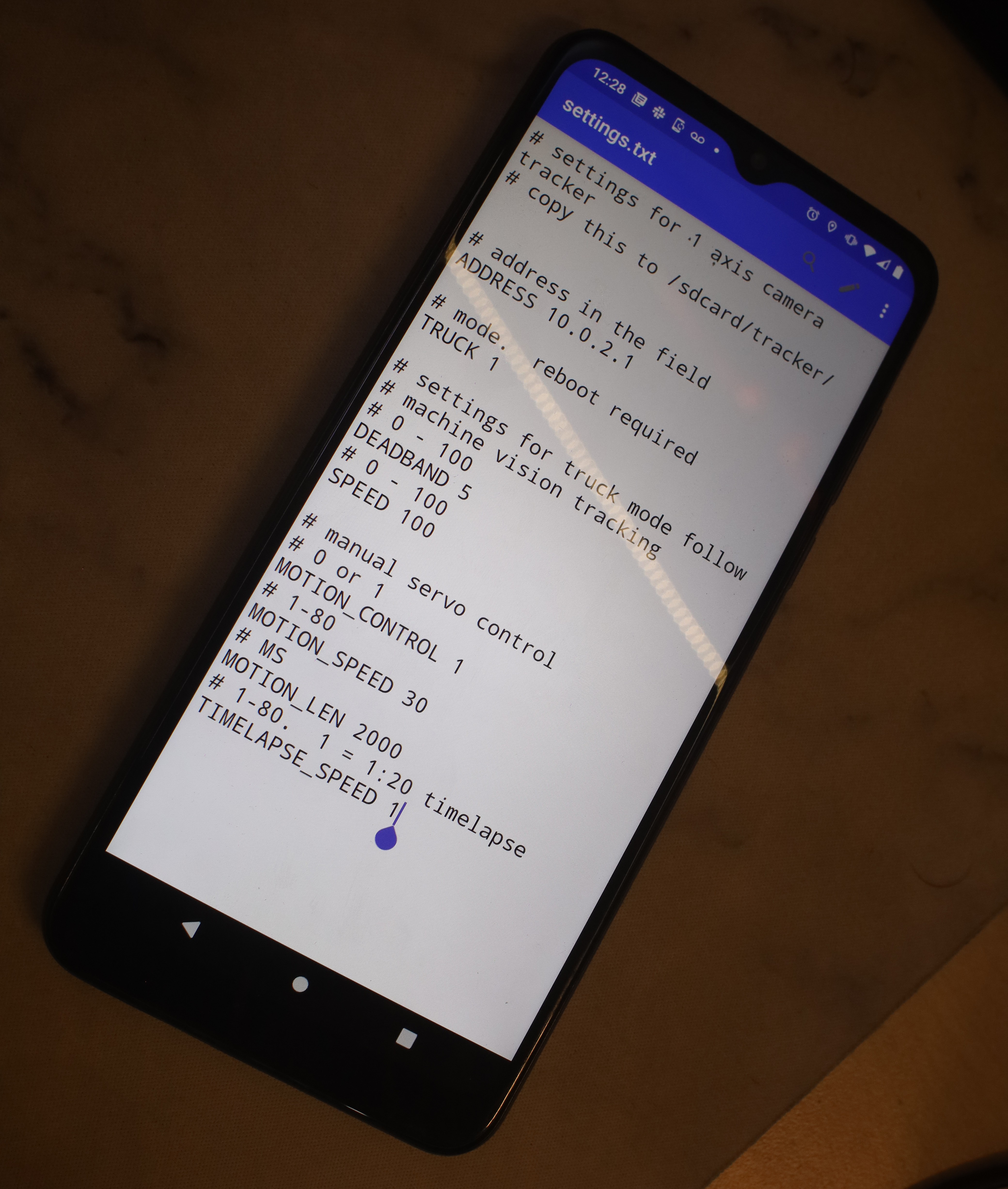







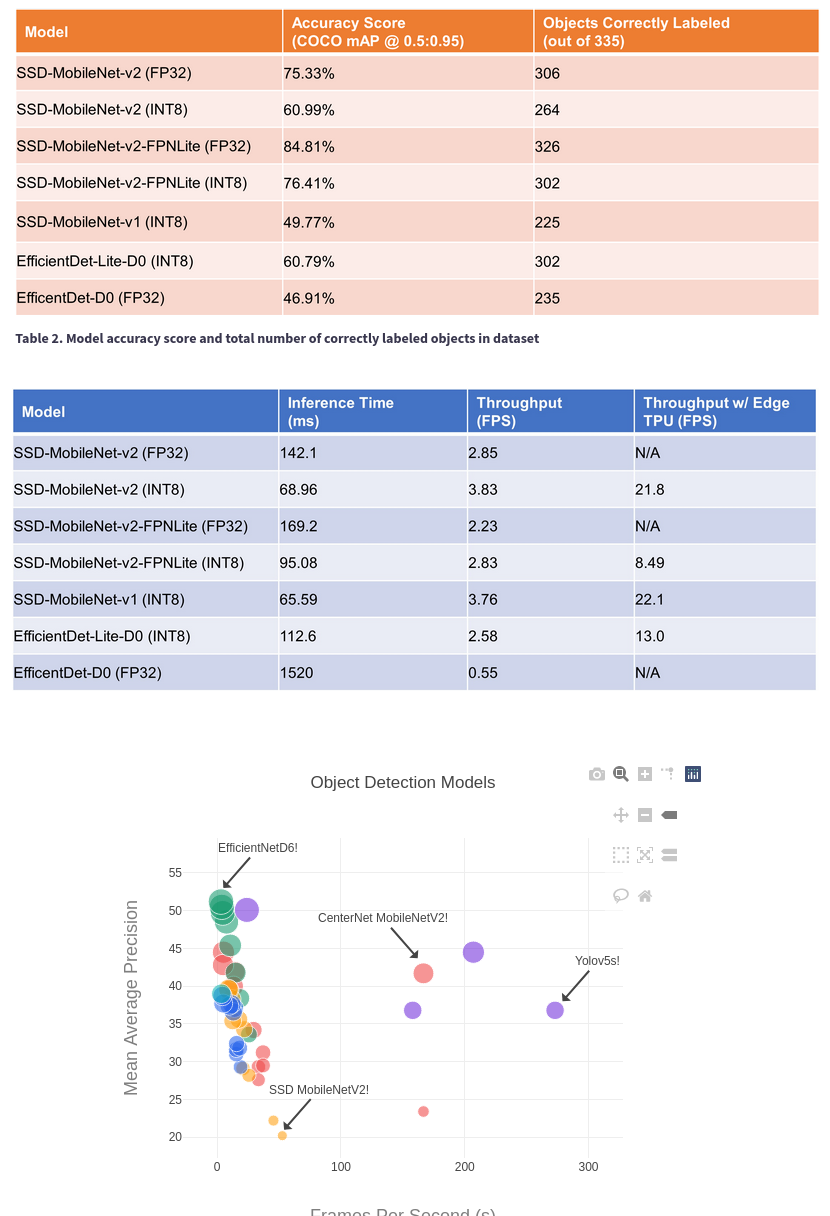
 More testing with pretrained efficientdet-lite0. It's already known that this model hits trees & light posts.
More testing with pretrained efficientdet-lite0. It's already known that this model hits trees & light posts.








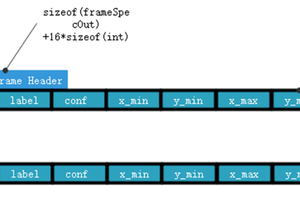
 Johanna Shi
Johanna Shi
 Jared (jostmey)
Jared (jostmey)